Written an article on implementing a toy O(n^2) N-body simulation algorithm with High Performance Computing (HPC) and Intel Xeon Phi Architecture. In Part 1, we describe the code optimization journey to boost performance from 3.2 to 2831 GFLOPS on a single node. In Part 2, we distribute workload across 16 cluster nodes to further boost performance to 33208 GFLOPS. End result: capable of performing over 1 trillion (1,099,510,579,200) particle-to-particle interactions per time-step at sub-second level (~662 ms).
Tag Archives: C++
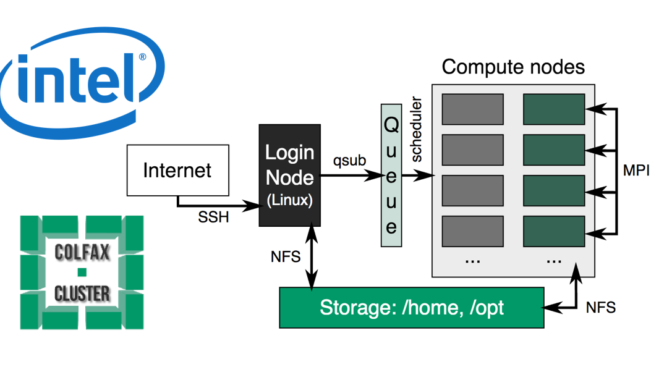
Intel Colfax Cluster – Optimize a Numerical Integration Implementation with Parallel Programming and Distributed Computing
Intel Colfax Cluster – Distributed Computing and Parallel Programming – Hello World Application
Intel Colfax Cluster – Parallel a For Loop Application On Xeon Phi (Knights Landing) Cluster Node
Intel Colfax Cluster – Write And Run a Simple Parallel Application On Xeon Phi (Knights Landing) Cluster Node
Intel Colfax Cluster – How to run an application in High Bandwidth Mode (HBM) on Xeon Phi (Knights Landing) enabled Cluster Node
Accelerated C++ Solution to Exercise 7-9
Exercise 7-9
(difficult) The implementation of nrand in S7.4.4/135 will not work for arguments greater than RAND_MAX. Usually, this restriction is no problem, because RAND_MAX is often the largest possible integer anyway. Nevertheless, there are implementations under which RAND_MAX is much smaller than the largest possible integer. For example, it is not uncommon for RAND_MAX to be 32767 (2^15 -1) and the largest possible integer to be 2147483647 (2^31 -1). Reimplement nrand so that it works well for all values of n.
Solution
This exercise is great – it gives us the chance to create and understand an algorithm that generate random number beyond RAND_MAX (the largest default C++ random number that can be “reached” by the rand() function) whilst ensuring even probability distribution of that random number (i.e. the number “10” having the same chance of getting picked as the number “234”, etc.).
Andrew and Barbara (the authors) provided the original code for this exercise on GitHub here back in year 2000. I took the liberty to read through it with the aim of understanding and making sense of the solution. After 3 evenings of sketching diagrams in my notepad (and getting stuck multiple times), I eventually understood the underlying principle / concepts, and managed to come up with an algorithm built on the authors’ original solution (with slight differences).
In this post I shall illustrate the derivation and implementation of the algorithm (which I can actually visualise). I use PowerPoint to draw out some diagrams to aid visualising the algorithms. I would like to express my sincerest thanks to Andrew and Barbara for this very wonderful exercise.
What Will Our nrand() Do?
We are going to create a function nrand() that returns a random integer, given the asymmetric range [0, randomOutcomeLimit).
e.g. if randomOutcomeLimit is 4, then the randomOutcome may be either 0, 1, 2, 3 – each with an equal (25%) chance of getting picked.
Terminologies
Before going any further, I believe it is a good idea to define some core variables / terminologies.
- randomDriver: this is essentially rand(). The C++ default (seeding) random number that span within the asymmetric range [0, randomDriverLimit). We use randomDriver to “drive” (or compute) the eventual randomOutcome.
- randomDriverLimit: this is RAND_MAX + 1. i.e. “one-above” the maximum possible randomDriver value.
- randomOutcome: this is the random number that gets returned. It spans within the symmetric range [0, randomOutcomeLimit). The algorithm ensures that every single randomOutcome has the same probability of getting randomly selected. The randomOutcome is “driven” (or determined) by the randomDriver.
- randomOutcomeLimit: “one-above” the maximum possible randomOutcome value.
- bucketSize: this is “the glue” between randomDriver and randomOutcome. Think of it as the ratio between the two. To enable us to translate a randomDriver into a randomOutcome (and vice versa).
- remainder: this is used in the computation of randomOutcome. Only relevant for the case whhen randomOutcomeLimit > randomDriverLimit.
Note: in the “pseudo diagrams” that I have drawn up in PowerPoint, I shall use RD to represent randomDriver, and RO to represent randomOutcome.
Algorithm
The algorithm for nrand() will cater for two scenarios:
- Case 1: when randomOutcomeLimit <= randomDriverLimit
- Case 2: when randomOutcomeLimit > randomDriverLimit
It may be easier if I display the complete nrand.cpp code here now, and walk through in more details afterwards.
The nrand.cpp Code
#include <cmath> // ceil
#include <cstdlib> // rand, RAND_MAX, srand
#include <stdexcept> // domain_error
using std::ceil;
using std::rand;
using std::domain_error;
// Asymmetric ranges:
// randomOutcome: [0, randomOutcomeLimit)
// randomDriver: [0, randomDriverLimit)
int nrand(int randomOutcomeLimit) {
if (randomOutcomeLimit <= 0)
throw domain_error("Argument to nrand is out of range");
int randomOutcome;
int randomDriverLimit = RAND_MAX + 1;
if (randomOutcomeLimit <= randomDriverLimit) {
const int bucketSize = randomDriverLimit / randomOutcomeLimit;
do {
int bucket = rand() / bucketSize;
randomOutcome = bucket;
} while (randomOutcome >= randomOutcomeLimit);
} else {
const int bucketSize = ceil(randomOutcomeLimit / randomDriverLimit);
do {
int bucket = nrand(randomDriverLimit);
int remainder = nrand(bucketSize);
randomOutcome = (bucket * bucketSize) + remainder;
} while (randomOutcome >= randomOutcomeLimit);
}
return randomOutcome;
}
Case 1: when randomOutcomeLimit <= randomDriverLimit
if (randomOutcomeLimit <= randomDriverLimit) {
const int bucketSize = randomDriverLimit / randomOutcomeLimit;
do {
int bucket = rand() / bucketSize;
randomOutcome = bucket;
} while (randomOutcome >= randomOutcomeLimit);
}
Since the values of randomOutcomeLimit and randomDriverLimit are pre-defined, we compute our bucketSize by taking the ratio between the two. We use the randomDriverlimit as the numerator (and randomDriverLimit as the denominator) to ensure this ratio is a non-fraction. Think of bucketSize as: “The number of randomDrivers per randomOutcome”. 10 randomDrivers per randomOutcome makes sense. 0.5 randomDrivers per randomOutcome does not.
Note that the equation automatically “round-down” the ratio to the integer (instead of “round-up”). This is to ensure every single randomOutcome to have the same probability of being picked.
To illustrate this, assume we have randomDriverLimit = 5 (i.e. RAND_MAX = 4. i.e. randomDriver may be 0, 1, 2, 3.), and randomOutcomeLimit = 2 (i.e. randomOutcome maybe 0 and 1).
Compute bucketSize With “Round-down” (desirable)
In the case of computing bucketSize using “round-down”, the probability distribution of randomOutcome is even. This is what we want in a random number generator.

Compute bucketSize With “Round-up” (Un-desirable)
In the case of computing bucketSize using “round-up”, the probability distribution of randomOutcome is non-even. This is what we DO NOT want in a random number generator.

Further Visualisation
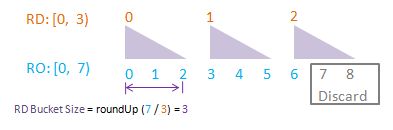
To visualise randomDriver, randomDriverLimit, randomOutcome, randomOutcomeLimit, bucket, and bucketSize all in one go, I have put together some PowerPoint diagrams here which I believe will speak for themselves without the need of much further (wordy) explanations! I assume a fixed randomDriverLimit of 21, and vary the randomOutcomeLimit for illustrations.
Visualise: randomDriverLimit of 21, randomOutcomeLimit = 2.
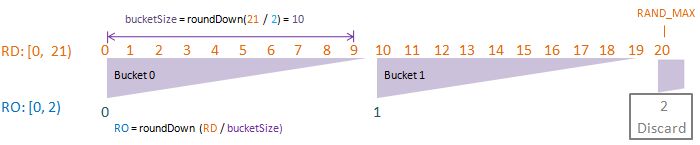
Visualise: randomDriverLimit of 21, randomOutcomeLimit = 3.
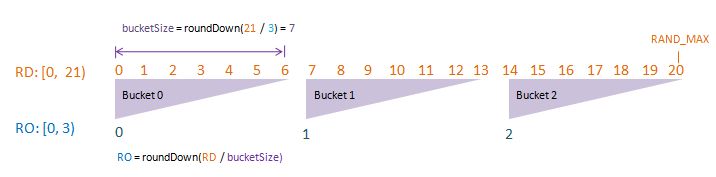
Visualise: randomDriverLimit of 21, randomOutcomeLimit = 4.

Visualise: randomDriverLimit of 21, randomOutcomeLimit = 5.
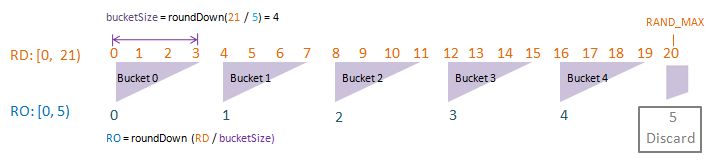
Visualise: randomDriverLimit of 21, randomOutcomeLimit = 6.
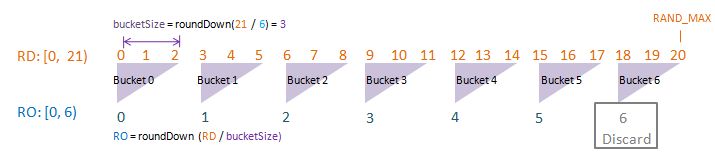
Visualise: randomDriverLimit of 21, randomOutcomeLimit = 7.
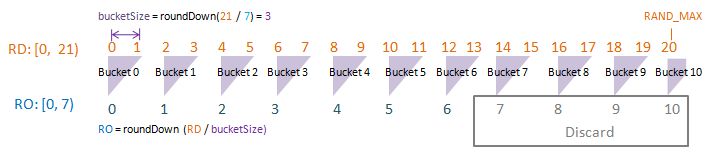
Visualise: randomDriverLimit of 21, randomOutcomeLimit = 11.

Case 2: when randomOutcomeLimit > randomDriverLimit
} else {
const int bucketSize = ceil(randomOutcomeLimit / randomDriverLimit);
do {
int bucket = nrand(randomDriverLimit);
int remainder = nrand(bucketSize);
randomOutcome = (bucket * bucketSize) + remainder;
} while (randomOutcome >= randomOutcomeLimit);
}
We compute bucketSize in a similar manner as Case 1, except that we use “round-up” (i.e. using the “ceil” function in C++) instead of “round-down”. We also ensure a non-fraction bucketSize (as explained in Case 1), by putting randomOutcomeLimit as the numerator, and randomDriverLimit as the denominator. Think of bucketSize as: “The number of randomOutcome per randomDriver”. 10 randomOutcomes per randomRandomDriver makes sense. 0.5 randomOutcome per randomRandomDriver does not.
We use “round-up” in the computation of the bucketSize to ensure the entire range of randomDriver can “cover” the entire range of randomOutcome. I can illustrate this point easily via some diagrams as followings.
In addition, we use nrand recursively downstream. Unfortunately I am not able to explain this bit in words. I would however recommend to look at the diagrams in the following section – looking at these diagrams have helped in understanding how the remaining steps hang together. I hope you may be able to figure this out for yourself too! (use the diagrams!).
Compute bucketSize With “Round-down” (un-desirable)

Compute bucketSize With “Round-up” (desirable)

Further Visualisation
To visualise randomDriver, randomDriverLimit, randomOutcome, randomOutcomeLimit, bucket, and bucketSize all in one go, I have put together some PowerPoint diagrams here which I believe will speak for themselves without the need of much further (wordy) explanations! I assume a fixed randomDriverLimit of 2, and vary the randomOutcomeLimit for illustrations.
Visualise: randomDriverLimit of 2, randomOutcomeLimit = 5.

Visualise: randomDriverLimit of 2, randomOutcomeLimit = 6.

Visualise: randomDriverLimit of 2, randomOutcomeLimit = 7.

Visualise: randomDriverLimit of 3, randomOutcomeLimit = 5.
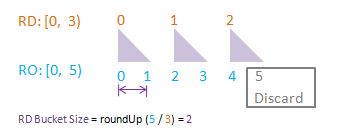
Visualise: randomDriverLimit of 3, randomOutcomeLimit = 6.
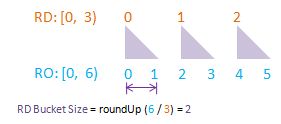
Visualise: randomDriverLimit of 3, randomOutcomeLimit = 7.
The Project
To wrap up the entire projects I shall document the C++ header and source files here. The nrand algorithm aims to generate random numbers within the range [0, randomOutcomeLimit) in an even probability distribution – i.e. each random outcome has the same chance of being picked.
Source File List
Header File List
Source Files
main.cpp
#include <iostream> // std::cout, std::cin, std::endl
#include <cstdlib> // RAND_MAX, srand
#include <ctime> // std::time
#include "nrand.h" // nrand
using std::cout;
using std::cin;
using std::endl;
using std::srand;
using std::time;
int main()
{
// Uncomment this line to see new randomness every time the job is run.
srand(time(NULL));
// Generate random numbers within the range [0, n)
const int n = 999999999; // try n = 10, and n = 3276700
const int numbersPerLine = 5;
// Display the limits
cout << "randomOutcomeLimit: " << n << endl;
cout << "randomDriverLimit: " << (RAND_MAX + 1) << endl;
// Display the randomOutcomes
for (int i = 0; i != 100; ++i) {
if (i == 0)
cout << nrand(n);
else {
cout << ", " << nrand(n);
// start a new line
if (i != 0 && (i+1) % numbersPerLine == 0)
cout << endl;
}
}
return 0;
}
nrand.cpp
#include <cmath> // ceil
#include <cstdlib> // rand, RAND_MAX, srand
#include <stdexcept> // domain_error
using std::ceil;
using std::rand;
using std::domain_error;
// Asymmetric ranges:
// randomOutcome: [0, randomOutcomeLimit)
// randomDriver: [0, randomDriverLimit)
int nrand(int randomOutcomeLimit) {
if (randomOutcomeLimit <= 0)
throw domain_error("Argument to nrand is out of range");
int randomOutcome;
int randomDriverLimit = RAND_MAX + 1;
if (randomOutcomeLimit <= randomDriverLimit) {
const int bucketSize = randomDriverLimit / randomOutcomeLimit;
do {
int bucket = rand() / bucketSize;
randomOutcome = bucket;
} while (randomOutcome >= randomOutcomeLimit);
} else {
const int bucketSize = ceil(randomOutcomeLimit / randomDriverLimit);
do {
int bucket = nrand(randomDriverLimit);
int remainder = nrand(bucketSize);
randomOutcome = (bucket * bucketSize) + remainder;
} while (randomOutcome >= randomOutcomeLimit);
}
return randomOutcome;
}
Header Files
nrand.h
#ifndef GUARD_NRAND_H #define GUARD_NRAND_H // nrand.h int nrand(int); #endif // GUARD_NRAND_H
Test Result
Test Case 1: when randomOutcomeLimit > randomDriverLimit
Set randomOutcomeLimit (i.e. the “n” in the main program) = 10. (randomDriverLimit on my Windows Vista System is 32768. i.e. RAND_MAX = 32767).
randomOutcomeLimit: 10 randomDriverLimit: 32768 0, 7, 3, 4, 5 , 2, 3, 5, 7, 8 , 5, 1, 0, 9, 1 , 0, 1, 2, 5, 3 , 1, 3, 5, 9, 1 , 8, 4, 8, 8, 8 , 2, 6, 8, 1, 4 , 5, 4, 5, 7, 4 , 7, 5, 1, 2, 0 , 5, 7, 3, 6, 9 , 8, 6, 5, 6, 4 , 4, 3, 2, 2, 5 , 9, 3, 0, 2, 7 , 8, 8, 1, 7, 1 , 4, 2, 3, 0, 0 , 8, 1, 2, 5, 9 , 4, 2, 5, 9, 9 , 7, 4, 3, 0, 4 , 9, 5, 6, 8, 0 , 4, 1, 6, 5, 2 Process returned 0 (0x0) execution time : 0.293 s Press any key to continue.
Test Case 2: when randomOutcomeLimit <= randomDriverLimit
Set randomOutcomeLimit (i.e. the “n” in the main program) = 999999999. (randomDriverLimit on my Windows Vista System is 32768. i.e. RAND_MAX = 32767).
randomOutcomeLimit: 999999999 randomDriverLimit: 32768 40716497, 545497019, 401935189, 573265717, 87747530 , 675712555, 451019252, 549144813, 442862664, 914580320 , 3346215, 284749221, 212065917, 568356864, 979714558 , 544197549, 418473188, 720009720, 433822531, 424721581 , 541414236, 257758341, 608087599, 83473957, 984179693 , 492106188, 331214530, 521536020, 935375395, 580651497 , 195237728, 664468742, 414572965, 645131011, 682450472 , 477285531, 969901982, 319040147, 723433358, 897986272 , 120072600, 13688281, 426975024, 332152250, 774858930 , 85086071, 749114164, 49610236, 923599508, 602891952 , 599691044, 621946048, 156375628, 885810442, 918023686 , 135602107, 449128117, 661074165, 86314758, 699792585 , 461395423, 916830653, 398552621, 933505532, 326772882 , 142535635, 570358869, 573805944, 391791222, 527897950 , 942405333, 383272295, 777643889, 483575430, 421364976 , 808711544, 623226506, 83231569, 970354625, 918738412 , 272996097, 134992162, 663575905, 719215842, 172551438 , 345021838, 170806050, 154762077, 794127443, 949285447 , 81891829, 62877966, 418973269, 343240040, 888728945 , 627644733, 808847443, 814885588, 628243461, 188955197 Process returned 0 (0x0) execution time : 0.415 s Press any key to continue.
Reference
Koenig, Andrew & Moo, Barbara E., Accelerated C++, Addison-Wesley, 2000Accelerated C++ Solution to Exercise 7-8
Exercise 7-8
Change the cross-reference program to find all the URLs in a file, and write all the lines on which each distinct URL occurs.
Solution
This is surprisingly easy if you have completed the previous exercises. Chapter 7 of the book has provided the instruction to solve this. This exerise is about “doing it”.
This is the solution strategy:
- Use the entire project as per Solution to Exercise 7-7. i.e. main.cpp, split.cpp/.h, xref.cpp/.h.
- Add the find_url function components as per Solution to Exercise 6-0 (Part 4 / 7). i.e. find_urls.cpp/.h, not_url_char.cpp/.h, url_beg.cpp/.h, url_end.cpp/.h.
- Update the main function so that this bit of code…
// Call xref using split by default. map<string, vector<int> > ret = xref(cin);
… is replaced by this (using find_urls)….
// Call xref using find_urls (instead of the default split) map<string, vector<int> > ret = xref(cin, find_urls);
Though split.cpp and split.h will not be called directly, the function split may is included by the xref function. So for safety, I will leave it in the project.
The Project
In the following section I, for clarity sake, I shall include the entire project (C++ header and source files).
Source File List
Header File List
Source Files
main.cpp
#include <iostream> // std::cin, std::cout, std::endl
#include <map> // std::map
#include <string> // std::string
#include <vector> // std::vector
#include "xref.h" // xref
#include "find_urls.h" // find_urls
using std::cin;
using std::cout;
using std::endl;
using std::map;
using std::string;
using std::vector;
// Find all the lines that refer to each word in the input
// (S7.3/128)
int main() {
// Call xref using find_urls (instead of the default split)
map<string, vector<int> > ret = xref(cin, find_urls);
// Write the results.
for (map<string, vector<int> >::const_iterator it = ret.begin(); it != ret.end(); ++it) {
// Find number of lines the word has appeared
vector<int>::size_type numLines = (it->second).size();
// Write the word
cout << it->first << " occurs on ";
if (numLines == 1)
cout << "line: ";
else
cout << "lines: ";
// Followed by one or more line numbers.
vector<int>::const_iterator line_it = it->second.begin();
cout << *line_it; // write the first line number
++line_it;
// Write the rest of the line numbers, if any.
while (line_it != it->second.end()) {
cout << ", " << *line_it;
++line_it;
}
// Write a new line to separate each word from the next.
cout << endl;
}
return 0;
}
find_urls.cpp
#include <string> // string
#include <vector> // vector
#include "url_beg.h" // url_beg
#include "url_end.h" // url_end
using std::string;
using std::vector;
vector<string> find_urls(const string& s) {
vector<string> ret;
typedef string::const_iterator iter;
iter b = s.begin(), e = s.end();
// look through the entire input
while (b != e) {
// look for one or more letters followed by ://
b = url_beg(b, e);
// if we found it
if (b != e) {
// get the rest of the URL
iter after = url_end(b, e);
// remember the URL
ret.push_back(string(b, after));
// advance b and check for more URLs on this line
b = after;
}
} return ret;
}
not_url_char.cpp
#include <string> // string, isalnum
#include <algorithm> // find
using std::string;
bool not_url_char(char c) {
// characters, in addition to alphanumerics, that can appear in a URL
static const string url_ch = "~;/?:@=&$-_.+!*'(),";
// see whether c can appear in a URL and return the negative
return !(isalnum(c) || find(url_ch.begin(), url_ch.end(), c) != url_ch.end() );
}
split.cpp
#include <string> // string
#include <vector> // vector
#include <cctype> // isspace
#include <algorithm> // find_if
using std::vector;
using std::string;
using std::isspace;
using std::find_if;
// true if the argument is whitespace, false otherwise
// (S6.1.1/103)
bool space(char c) { return isspace(c); }
// false if the argument is whitespace, true otherwise
// (S6.1.1/103)
bool not_space(char c) { return !isspace(c); }
// Scan a line and split into words. Return a vector that contains these words.
// (S6.1.1/103)
vector<string> split(const string& str) {
typedef string::const_iterator iter; vector<string> ret;
iter i = str.begin(); while (i != str.end()) {
// Ignore leading blanks
i = find_if(i, str.end(), not_space);
// Find end of next word
iter j = find_if(i, str.end(), space);
// Copy the characters in ([i, j)
if (i != str.end())
ret.push_back(string(i, j));
// Re-initialize
i = j;
}
return ret;
}
url_beg.cpp
#include <string> // string, isalpha
#include <algorithm> // search
#include "not_url_char.h" // not_url_char
using std::string;
string::const_iterator url_beg(string::const_iterator b, string::const_iterator e) {
static const string sep = "://";
typedef string::const_iterator iter;
// i marks where the separator was found iter i = b;
while ((i = search(i, e, sep.begin(), sep.end() )) != e) {
// make sure the separator isn't at the beginning or end of the line
if (i != b && i + sep.size() != e) {
// beg marks the beginning of the protocol-name
iter beg = i;
while (beg != b && isalpha(beg[-1]))
--beg;
// is there at least one appropriate character before and after the separator?
if (beg != i && !not_url_char(i[sep.size()]))
return beg;
}
// the separator we found wasn't part of a URL; advance i past this separator
i += sep.size();
}
return e;
}
url_end.cpp
#include <string> // string
#include <vector> // vector
#include <algorithm> // find_if
#include "not_url_char.h" // not_url_char
using std::string;
string::const_iterator url_end(string::const_iterator b, string::const_iterator e) {
return find_if(b, e, not_url_char);
}
xref.cpp
#include <iostream> // std::cin, std::istream
#include <map> // std::map
#include <string> // std::string
#include <vector> // std::vector
#include <algorithm> // std::find
#include "split.h" // split
using std::cin;
using std::map;
using std::string;
using std::vector;
using std::istream;
using std::find;
// Find all the lines that refer to each word in the input
// In this program, the first line is represented by line 1,
// second line is represented by line 2, etc.
// (S7.3/126)
// Adjusted as per Exercise 7-3: store only non-duplicated line numbers.
map<string, vector<int> > xref(istream& in, vector<string> find_words(const string&) = split) {
string line; int line_number = 0; map<string, vector<int> > ret; // map string to vector<int>
// Read the next line while (getline(in, line)) { ++line_number;
// Break the input line into words
vector<string> words = find_words(line);
// remember that each word occurs on the current line
for (vector<string>::const_iterator it = words.begin();
it != words.end(); ++it) {
// store only non-duplicated line numbers.
if ( find( ret[*it].begin(), ret[*it].end(), line_number) == ret[*it].end() )
ret[*it].push_back(line_number);
}
}
return ret;
}
Header Files
find_urls.h
#ifndef GUARD_FIND_URLS_H #define GUARD_FIND_URLS_H #include <vector> #include <string> std::vector<std::string> find_urls(const std::string&); #endif // GUARD_FIND_URLS_H
not_url_char.h
#ifndef GUARD_NOT_URL_CHAR_H #define GUARD_NOT_URL_CHAR_H bool not_url_char(char); #endif // GUARD_NOT_URL_CHAR_H
split.h
#ifndef GUARD_SPLIT_H #define GUARD_SPLIT_H #include <vector> #include <string> std::vector<std::string> split(const std::string&); #endif // GUARD_SPLIT_H
url_beg.h
#ifndef GUARD_URL_BEG_H #define GUARD_URL_BEG_H std::string::const_iterator url_beg(std::string::const_iterator, std::string::const_iterator); #endif // GUARD_URL_BEG_H
url_end.h
#ifndef GUARD_URL_END_H #define GUARD_URL_END_H #include <string> std::string::const_iterator url_end(std::string::const_iterator, std::string::const_iterator); #endif // GUARD_URL_END_H
xref.h
#ifndef GUARD_XREF_H #define GUARD_XREF_H // xref.h #include <iostream> // std::istream #include <map> // std::map #include <string> // std::string #include <vector> // std::vector #include "split.h" // split std::map<std::string, std::vector<int> > xref(std::istream&, std::vector<std::string> find_words(const std::string&) = split); #endif // GUARD_XREF_H
Test Result
Run the program and submit some random text confirms the program works as expected.
hello world http://google.co.uk and http://bbc.co.uk and http://yahoo.com and maybe http://google.co.uk also http://bbc.co.uk and http://yahoo.com and of course http://google.co.uk and finally http://w3schools.com and http://google.com ^Z http://bbc.co.uk occurs on lines: 1, 3 http://google.co.uk occurs on lines: 1, 2, 5 http://google.com occurs on line: 7 http://w3schools.com occurs on line: 6 http://yahoo.com occurs on lines: 2, 4
Reference
Koenig, Andrew & Moo, Barbara E., Accelerated C++, Addison-Wesley, 2000
Accelerated C++ Solution to Exercise 7-7
Exercise 7-7
Change the driver for the cross-reference program so that it writes line if there is only one line and lines otherwise.
Solution
The solution to this exercise is surprisingly simple. To clarify the question a bit – it essentially asks us to have some sort of if-else condition in place.
For instance…
- If the word “apple” occurs only on one line, we print “apple occurs on line: ” (followed by the line number).
- Otherwise, if the word “apple” occurs on multiple lines, we print “apple occurs on lines: ” (followed by the line numbers).
Recall that the Solution to Exercise 7-3 already provides the skeleton project that reports non-duplicated word occurrence line numbers. It therefore makes sense to use that project as the baseline project, and do the adjustment on top of it.
It turns out that there is only one small bit of code that needs changing, and it resides at the main.cpp file (the main function).
This is the original snippet within the main function:
// Write the word
cout << it->first << " occurs on line(s): ";
We can change it easily to the following to achieve that if-else conditioning. We essentially resolves the number of non-duplicate line occurences for the word beforehand. We can then use it to construct the if-else logic and display either “line” or “lines” accordingly.
// Find number of lines the word has appeared
vector<int>::size_type numLines = (it->second).size();
// Write the word
cout << it->first << " occurs on ";
if (numLines == 1)
cout << "line: ";
else
cout << "lines: ";
Surprisingly simple.
The Project
Simply…
- Re-use that Project as per Solution to Exercise 7-3.
- Replace the main.cpp file as per followings.
#include <iostream> // std::cin, std::cout, std::endl
#include <map> // std::map
#include <string> // std::string
#include <vector> // std::vector
#include "xref.h" // xref
using std::cin;
using std::cout;
using std::endl;
using std::map;
using std::string;
using std::vector;
// Find all the lines that refer to each word in the input
// (S7.3/128)
int main()
{
// Call xref using split by default.
map<string, vector<int> > ret = xref(cin);
// Write the results.
for (map<string, vector<int> >::const_iterator it = ret.begin();
it != ret.end(); ++it) {
// Find number of lines the word has appeared
vector<int>::size_type numLines = (it->second).size();
// Write the word
cout << it->first << " occurs on ";
if (numLines == 1)
cout << "line: ";
else
cout << "lines: ";
// Followed by one or more line numbers.
vector<int>::const_iterator line_it = it->second.begin();
cout << *line_it; // write the first line number
++line_it;
// Write the rest of the line numbers, if any.
while (line_it != it->second.end()) {
cout << ", " << *line_it;
++line_it;
}
// Write a new line to separate each word from the next.
cout << endl;
}
return 0;
}
Test Result
Running this new version main code gives us the result as expected.
apple orange banana orange orange apple banana mango ^Z apple occurs on lines: 1, 3 banana occurs on lines: 1, 3 mango occurs on line: 4 orange occurs on lines: 1, 2
Reference
Koenig, Andrew & Moo, Barbara E., Accelerated C++, Addison-Wesley, 2000Accelerated C++ Solution to Exercise 7-6
Exercise 7-6
Reimplement the gen_sentence program using two vectors: One will hold the fully unwound, generated sentence, and the other will hold the rules and will be used as a stack. Do not use any recursive calls.
Solution
After spending hours scratching my head and still getting stuck on this question, I decided to turn to Google for help. Eventually I discovered this Github Solution Code (uploaded by the Author himself) to this exercise. For the sake of learning, I simply picked out the “bits and pieces” from the Author’s code (such as the core concepts and snippets) and integrated these to my own solution. So let me disclose this upfront – the solution that you are seeing in this page is a result of the great help and pointer from the Author himself. Nevertheless, I believe it is the right thing to do to at least try and understand how the core concept work. The mission of this post is to add some additional documentation to demonstrate that we actually understand the concepts and techniques presented by the Author.
In the followings, I shall:
- Disclose the project (i.e. the C++ source and header files) that I use in my learning.
- Test run the job to confirm that it works.
- Demonstrate that we understand the new concept by manually draw out the step by step logic.
The Project
First, open the baseline project (i.e. the C++ source and header files) as per Solution to Exercise 7-0 (Part 3 / 3). Once the baseline project is opened up in (say) Code::Block, replace the following files with the newer version.
- gen_aux.h – use this newer version.
- gen_aux.cpp – use this newer version.
- gen_sentence.cpp – use this newer version.
Newer Version Souce and Header Files
This summarises the newer version source and header files.
gen_aux.h
#ifndef GUARD_GEN_AUX_H
#define GUARD_GEN_AUX_H
// gen_aux.h
#include <string> // std::string
#include <vector> // std::vector
#include "read_grammar.h" // Grammar
void gen_aux(const Grammar&, const std::string&, std::vector<std::string>&,
std::vector<std::string>&);
#endif // GUARD_GEN_AUX_H
gen_aux.cpp
#include <string> // std::string
#include <vector> // std::vector
#include <stdexcept> // logic_error
#include "read_grammar.h" // Grammar, Rule, Rule_collection
#include "bracketed.h" // bracketed
#include "nrand.h" // nrand
using std::string;
using std::vector;
using std::logic_error;
// Look up the input Grammar, and expand
// (modified version of S7.4.3/132)
void gen_aux(const Grammar& g, const string& token,
vector<string>& sentence, vector<string>& tokens) {
if (!bracketed(token)) {
sentence.push_back(token);
} else {
// locate the rule that corresponds to `token'
Grammar::const_iterator it = g.find(token);
if (it == g.end())
throw logic_error("empty rule");
// fetch the set of possible rules
const Rule_collection& c = it->second;
// from which we select one at random
const Rule& r = c[nrand(c.size())];
// push rule's tokens onto stack of tokens
// (in reverse order, because we're pushing and popping from the back)
for (Rule::const_reverse_iterator i = r.rbegin(); i != r.rend(); ++i)
tokens.push_back(*i);
}
}
gen_sentence.cpp
#include <vector> // std::vector
#include <string> // std::string
#include "read_grammar.h" // Grammar
#include "gen_aux.h" // gen_aux
using std::vector;
using std::string;
// Generate a sentence based on a Grammar object
// (modified version of S7.4.3/132)
vector<string> gen_sentence(const Grammar& g) {
vector<string> sentence;
vector<string> tokens;
tokens.push_back("<sentence>");
while (!tokens.empty()) {
string token = tokens.back();
tokens.pop_back();
gen_aux(g, token, sentence, tokens);
}
return sentence;
}
Test Result
Note: the result might differ when you run the job due to the nrand(). Core concept remains true though.
<noun> cat <noun> dog <noun> table <noun-phrase> <noun> <noun-phrase> <adjective> <noun-phrase> <adjective> large <adjective> brown <adjective> absurd <verb> jumps <verb> sits <location> on the stairs <location> under the sky <location> wherever it wants <sentence> the <noun-phrase> <verb> <location> ^Z the large brown dog sits wherever it wants the table sits under the sky the cat jumps on the stairs the brown cat jumps under the sky the brown large brown cat sits wherever it wants
Understanding the concept
Let’s use the first output sentence to illustrate our understanding of the core concept used by the gen_sentence and gen_aux functions.
the large brown dog sits wherever it wants
The billion dollar question, how did the program generate this line?
To demonstrate my understanding, I’ve manually put together a couple of simple Excel tables to walk through the logic.
Recall that this is the input grammar table:
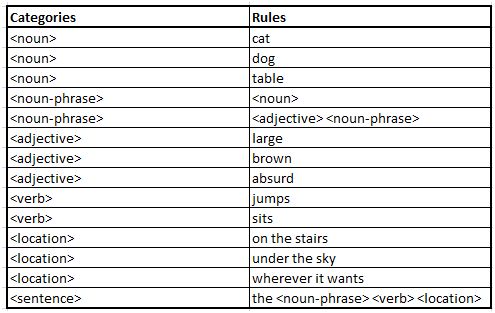
The gen_sentence and gen_aux can give the following output values:

Some Notes To This Example
For some extra clarity, I include here a brief explanation of what each column means.
tokens non-empty?
If non-empty, the while loop inside the gen_sentence step would keep expanding tokens and construct the string sentence. Otherwise, the while loop stop and we have our sentence! (Note that we start by expanding the top level “<sentence>”)
vector<string> sentence;
vector<string> tokens;
tokens.push_back("<sentence>");
while (!tokens.empty()) {
// some codes to expand <sentence> and construct the string sentence.
}
return sentence;
const string& token
This is the last element of tokens, implied by this statement within the gen_sentence step:
string token = tokens.back();
Is token bracketed?
If the token is bracketed, it implies the token corresponds to a Grammar category and need expanding. If it is not bracketed, we simply append the text the the string sentence.
if (!bracketed(token)) {
// some codes to construct the string sentence.
} else {
// some codes to expand the token.
}
const Rule& r
If the token is bracketed (i.e. a Grammar category), the const Rule& r is essentially the Grammar rule. I highlight this in orange.
vector<string>& sentence
If the token is not bracketed, we simply append the text to the string sentence. This column shows what the constructed string sentence look like. I highlight the newly appended element in blue.
(Updated) vector<string>& tokens
This is the interesting part and is updated by a combination of the gen_sentence and gen_aux steps.
- The tokens.pop_back() statement remove the last element of tokens (hence the strike-through in the table).
- If token (i.e. the token column) is bracketed, the for loop within the gen_aux function appends the entire rule (highlighted in orange) in reverse order. This is a very clever technique to get the tokens expand and string sentence constructed in the expected order. (it’s easier to visualise this via the Excel table above instead of explaning in writing!).
Summary
Walking through the logic as illustrated in the Excel table, the program generates and return the complete string sentence. The actual sentence may get constructed differently due to the nrand().