Tag Archives: HPC


How to setup PyTorch Jupyter Notebook on Intel Nervana AI Cluster (Colfax) For Deep Learning
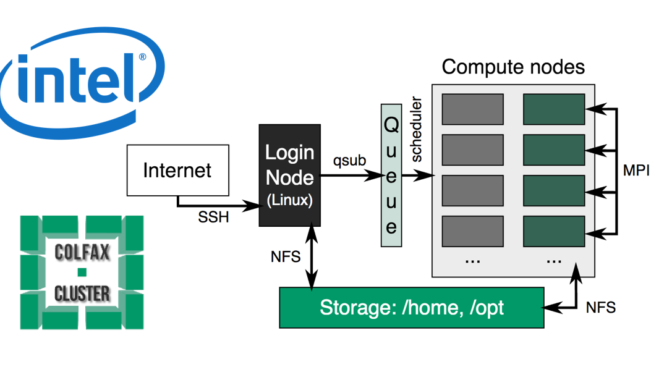
High Performance Computing (HPC) Running Intel Xeon Phi: N-body Simulation Example
Written an article on implementing a toy O(n^2) N-body simulation algorithm with High Performance Computing (HPC) and Intel Xeon Phi Architecture. In Part 1, we describe the code optimization journey to boost performance from 3.2 to 2831 GFLOPS on a single node. In Part 2, we distribute workload across 16 cluster nodes to further boost performance to 33208 GFLOPS. End result: capable of performing over 1 trillion (1,099,510,579,200) particle-to-particle interactions per time-step at sub-second level (~662 ms).