Exercise 7-6
Reimplement the gen_sentence program using two vectors: One will hold the fully unwound, generated sentence, and the other will hold the rules and will be used as a stack. Do not use any recursive calls.
Solution
After spending hours scratching my head and still getting stuck on this question, I decided to turn to Google for help. Eventually I discovered this Github Solution Code (uploaded by the Author himself) to this exercise. For the sake of learning, I simply picked out the “bits and pieces” from the Author’s code (such as the core concepts and snippets) and integrated these to my own solution. So let me disclose this upfront – the solution that you are seeing in this page is a result of the great help and pointer from the Author himself. Nevertheless, I believe it is the right thing to do to at least try and understand how the core concept work. The mission of this post is to add some additional documentation to demonstrate that we actually understand the concepts and techniques presented by the Author.
In the followings, I shall:
- Disclose the project (i.e. the C++ source and header files) that I use in my learning.
- Test run the job to confirm that it works.
- Demonstrate that we understand the new concept by manually draw out the step by step logic.
The Project
First, open the baseline project (i.e. the C++ source and header files) as per Solution to Exercise 7-0 (Part 3 / 3). Once the baseline project is opened up in (say) Code::Block, replace the following files with the newer version.
Newer Version Souce and Header Files
This summarises the newer version source and header files.
gen_aux.h
#ifndef GUARD_GEN_AUX_H
#define GUARD_GEN_AUX_H
// gen_aux.h
#include <string> // std::string
#include <vector> // std::vector
#include "read_grammar.h" // Grammar
void gen_aux(const Grammar&, const std::string&, std::vector<std::string>&,
std::vector<std::string>&);
#endif // GUARD_GEN_AUX_H
gen_aux.cpp
#include <string> // std::string
#include <vector> // std::vector
#include <stdexcept> // logic_error
#include "read_grammar.h" // Grammar, Rule, Rule_collection
#include "bracketed.h" // bracketed
#include "nrand.h" // nrand
using std::string;
using std::vector;
using std::logic_error;
// Look up the input Grammar, and expand
// (modified version of S7.4.3/132)
void gen_aux(const Grammar& g, const string& token,
vector<string>& sentence, vector<string>& tokens) {
if (!bracketed(token)) {
sentence.push_back(token);
} else {
// locate the rule that corresponds to `token'
Grammar::const_iterator it = g.find(token);
if (it == g.end())
throw logic_error("empty rule");
// fetch the set of possible rules
const Rule_collection& c = it->second;
// from which we select one at random
const Rule& r = c[nrand(c.size())];
// push rule's tokens onto stack of tokens
// (in reverse order, because we're pushing and popping from the back)
for (Rule::const_reverse_iterator i = r.rbegin(); i != r.rend(); ++i)
tokens.push_back(*i);
}
}
gen_sentence.cpp
#include <vector> // std::vector
#include <string> // std::string
#include "read_grammar.h" // Grammar
#include "gen_aux.h" // gen_aux
using std::vector;
using std::string;
// Generate a sentence based on a Grammar object
// (modified version of S7.4.3/132)
vector<string> gen_sentence(const Grammar& g) {
vector<string> sentence;
vector<string> tokens;
tokens.push_back("<sentence>");
while (!tokens.empty()) {
string token = tokens.back();
tokens.pop_back();
gen_aux(g, token, sentence, tokens);
}
return sentence;
}
Test Result
Note: the result might differ when you run the job due to the nrand(). Core concept remains true though.
<noun> cat
<noun> dog
<noun> table
<noun-phrase> <noun>
<noun-phrase> <adjective> <noun-phrase>
<adjective> large
<adjective> brown
<adjective> absurd
<verb> jumps
<verb> sits
<location> on the stairs
<location> under the sky
<location> wherever it wants
<sentence> the <noun-phrase> <verb> <location>
^Z
the large brown dog sits wherever it wants
the table sits under the sky
the cat jumps on the stairs
the brown cat jumps under the sky
the brown large brown cat sits wherever it wants
Understanding the concept
Let’s use the first output sentence to illustrate our understanding of the core concept used by the gen_sentence and gen_aux functions.
the large brown dog sits wherever it wants
The billion dollar question, how did the program generate this line?
To demonstrate my understanding, I’ve manually put together a couple of simple Excel tables to walk through the logic.
Recall that this is the input grammar table:
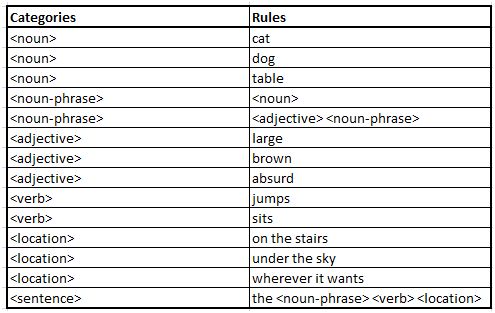
The gen_sentence and gen_aux can give the following output values:

Some Notes To This Example
For some extra clarity, I include here a brief explanation of what each column means.
tokens non-empty?
If non-empty, the while loop inside the gen_sentence step would keep expanding tokens and construct the string sentence. Otherwise, the while loop stop and we have our sentence! (Note that we start by expanding the top level “<sentence>”)
vector<string> sentence;
vector<string> tokens;
tokens.push_back("<sentence>");
while (!tokens.empty()) {
// some codes to expand <sentence> and construct the string sentence.
}
return sentence;
const string& token
This is the last element of tokens, implied by this statement within the gen_sentence step:
string token = tokens.back();
Is token bracketed?
If the token is bracketed, it implies the token corresponds to a Grammar category and need expanding. If it is not bracketed, we simply append the text the the string sentence.
if (!bracketed(token)) {
// some codes to construct the string sentence.
} else {
// some codes to expand the token.
}
const Rule& r
If the token is bracketed (i.e. a Grammar category), the const Rule& r is essentially the Grammar rule. I highlight this in orange.
vector<string>& sentence
If the token is not bracketed, we simply append the text to the string sentence. This column shows what the constructed string sentence look like. I highlight the newly appended element in blue.
(Updated) vector<string>& tokens
This is the interesting part and is updated by a combination of the gen_sentence and gen_aux steps.
- The tokens.pop_back() statement remove the last element of tokens (hence the strike-through in the table).
- If token (i.e. the token column) is bracketed, the for loop within the gen_aux function appends the entire rule (highlighted in orange) in reverse order. This is a very clever technique to get the tokens expand and string sentence constructed in the expected order. (it’s easier to visualise this via the Excel table above instead of explaning in writing!).
Summary
Walking through the logic as illustrated in the Excel table, the program generates and return the complete string sentence. The actual sentence may get constructed differently due to the nrand().
Reference
Koenig, Andrew & Moo, Barbara E., Accelerated C++, Addison-Wesley, 2000
The Github code solution uploaded by the author (A.Koening).