Exercise 4-6
Rewrite the Student_info structure, and the read and grade functions, so that they calculate each student’s grades as part of reading the input, and store only the final grade.
Solution
Having spent a couple of hours solving this problem, it reminds me of the typical experience at work. i.e. changing / updating some else’s code! I got there in the end :)
In this post I will:
- Describe the problem and solution in depth.
- Summarise my solution to this exercise – under the Project section.
- Run some tests using both the old and new solutions / programs – to confirm that we indeed get the same results.
Problem and Solution
The exercise requires us to re-write the chapter 4 partitioned textbook program (as demonstrated in my Solution to Exercise 4-0) in a way that will effectively change the structure of the Student_info object. Note also the new requirement to “calculate each student’s grades as part of reading the input, and store only the final grade” – i.e. we only store the final grade. We do not store the mid-term score, final-term score, and the homework scores in the Student_info objects. We can visualise this change in the Student_info.h header file.
Update the Student_info structure in Student_info.h
Before the change:
struct Student_info
{
std::string name;
double midterm;
double final;
std::vector<double> homework;
};
After the change:
struct Student_info
{
std::string name;
double final_grade;
};
In both cases we keep the string name as it is. The major differences are:
- During the “before” stage we store all input data (i.e. double midterm, double final, vector<double> homework) to the Student_info object. The program uses a downstream process to compute and display the double final_grade on the fly using a for loop. The double final_grade never get stored in the Student_info object.
- During “after” stage we read in all input data on the fly, and immediate use these to compute the double final_grade. We store the double final_grade to the Student_info object. We discard the input data (mid-term score, final-term score, and the homework scores).
The change of the Student_info object gives us an hint that, all functions that take the Student_info object as input, might need changing as well. If we following the main program, we bump into the:
while (read(cin, record)) { }
This corresponds to the function istream& read(istream&, Student_info&) in Student_info.cpp source file.
Update a read function in Student_info.cpp
The original function parse all the incoming data to the Student_info object.
Before the change:
istream& read(istream& is, Student_info& s)
{
// read and store the student's name and midterm and final exam grades
is >> s.name >> s.midterm >> s.final;
// read and store all the student's homework grades
read_hw(is, s.homework);
return is;
}
In the new version, we only wish to use the double midterm, double final, vector<double> homework temporarily purely for the purpose of computing the double final_grade. To do this, we can create local variables to cater for the temporarily usages, and only store the double final_grade in the end.
After the change:
istream& read(istream& is, Student_info& s)
{
double midterm;
double final;
vector<double> homework;
is >> s.name >> midterm >> final;
// read and store all the student's homework scores (to the temporary vector<double> container)
read_hw(is, homework);
// compute the student's overall score, and store to the Student_info object
try
{
s.final_grade = grade(midterm, final, homework);
}
catch (domain_error e)
{
s.final_grade = -1; // indicating student has done no homework
}
return is;
}
See that the new version function istream& read(istream&, Student_info&), parses the mid-term score to the local variable double midterm, the final-term score to the local variable double final, the homework scores to the local container vector<double> homework (using the read_hw function, which is unchanged).
I now have a try block to compute the double final_grade straight away (and store in the Student_info object) using the function grade(double, double, double), which is unchanged. If no error, the final_grade is stored in the Student_info object. Otherwise (when no homework is submitted. i.e. the homework vector is empty), then I force set the final_grade to -1 to imply no homework. As the score is always positive, we can be very certain that -1 is not the result of computation of the final_grade.
In summary, the enhanced read function enables us to “fill in” the values of the new Student_info structure – for each Student_info object, we require the student’s name, and the student’s (computed) final grade.
Update the main program to display report
The original main program contains a step to compute the double final_grade on the fly and display within a for loop. In the new version program we no longer need to compute double final_grade on the fly, as the read function above has taken care this and store the double final_grade away as a property of the Student_info object. In the new version main program, we just need to simply use the std::cout to display Student_info::final_grade.
Before the change
// write the names and grades
for (vector<Student_info>::size_type i = 0;
i != students.size(); ++i)
{
//write the name, padded on teh right to maxlen + 1 characters
cout << students[i].name
<< string(maxlen + 1 - students[i].name.size(), ' ');
//compute and write the grade
try
{
double final_grade = grade(students[i]);
streamsize prec = cout.precision();
cout << setprecision(3) << final_grade
<< setprecision(prec);
}
catch (domain_error e)
{
cout << e.what();
}
cout << endl;
}
After the change
// write the names and grades
for (vector<Student_info>::size_type i = 0;
i != students.size(); ++i)
{
// write the name, padded on the right to maxlen + 1 characters
cout << students[i].name
<< string(maxlen + 1 - students[i].name.size(), ' ');
streamsize prec = cout.precision();
// write the overall_grade out directly
cout << setprecision(3)
<< students[i].final_grade
<< setprecision(prec) << endl;
}
Note that the new version step purely display the results. Much simplier than the original version.
What we should also notice is that the new verrsion no longer require the use of the function double grade(const Student_info&) – we can safely remove this from both the grade.cpp source file and grade.h header file.
The Project – Putting Everything Together
I now wrap up the solution to this exercise by documenting the entire project – which is essentially and updated version of my Solution to Exercise 4-0. I have tried my best to highlight the “before” and “after” via commenting within the codes. I will run some tests at the end of the post using both the old and new solutions / programs – to confirm that we do indeed get the same results.
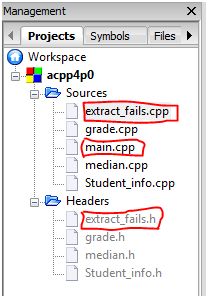
C++ Source Files
- main.cpp – this is the first program that is run during the implementation phase.
- grade.cpp – contains all functions relating to computing grades.
- median.cpp – contains all functions relating to computing median.
- Student_info.cpp – contains all functions relating to handling a Student_info object.
C++ Header Files
- grade.h – declare the functions as defined in grade.cpp
- median.h – declare the functions as defined in median.cpp
- Student_info.h – declare the functions as defined in Student_info.cpp, plus defining the data structure of the Student_info (object) type.
This diagram below shows what the Code::Block Management Tree look like after successful creation of these files (note that this is the same as the one in the Solution to Exercise 4-0).
Source Files
main.cpp
#include <algorithm>
#include <iomanip>
#include <ios>
#include <iostream>
/* #include <stdexcept> */ // Exercise 4-6: no longer required
#include <string>
#include <vector>
#include "grade.h"
#include "Student_info.h"
using std::cin;
using std::cout;
using std::endl;
/* using std::domain_error; */ // Exercise 4-6: no longer required
using std::max;
using std::setprecision;
using std::sort;
using std::streamsize;
using std::string;
using std::vector;
// Exercise 4-6: adjusted from the for loop onwards
int main()
{
vector<Student_info> students;
Student_info record;
string::size_type maxlen = 0; // the length of the longest name
// read and store all the student's data.
// Invariant: students contain all the student records read so far
// maxlen contains the length of the longest name in students
while (read(cin, record))
{
// find the length of longest name
maxlen = max(maxlen, record.name.size());
students.push_back(record);
}
// alphabetize the student records
sort(students.begin(), students.end(), compare);
// write the names and grades
for (vector<Student_info>::size_type i = 0;
i != students.size(); ++i)
{
// write the name, padded on the right to maxlen + 1 characters
cout << students[i].name
<< string(maxlen + 1 - students[i].name.size(), ' ');
streamsize prec = cout.precision();
// write the overall_grade out directly
cout << setprecision(3)
<< students[i].final_grade
<< setprecision(prec) << endl;
}
cout << endl;
cout << "*****************************************************************" << endl;
cout << "*** Note: a grade of -1 implies student has done no homework. ***" << endl;
cout << "*****************************************************************" << endl;
return 0;
}
grade.cpp
#include <stdexcept> // Exercise 4-6: added this
#include <vector>
#include "grade.h" // Exercise 4-6: added this
#include "median.h"
#include "Student_info.h"
using std::domain_error;
using std::vector;
// definitions for the grade functions from S4.1/52, S4.1.2/54, S4.2.2/63
// compute a student's overall grade from midterm and final exam
// grades and homework grade (S4.1/52)
double grade(double midterm, double final, double homework)
{
return 0.2 * midterm + 0.4 * final + 0.4 * homework;
}
// compute a student's overall grade from midterm and final exam grades
// and vector of homework grades.
// this function does not copy its argument, because median (function) does it for us.
// (S4.1.2/54)
double grade(double midterm, double final, const vector<double>& hw)
{
if (hw.size() == 0)
throw domain_error("student has done no homework");
return grade(midterm, final, median(hw));
}
// Exercise 4-6: the following function is no longer required.
/*
double grade(const Student_info& s)
{
return grade(s.midterm, s.final, s.homework);
}
*/
// source file for the median function
#include <algorithm>
#include <stdexcept>
#include <vector>
using std::domain_error;
using std::sort;
using std::vector;
// compute the median of a vector<double>
double median(vector<double> vec)
{
typedef vector<double>::size_type vec_sz;
vec_sz size = vec.size();
if (size == 0)
throw domain_error("median of an empty vector");
sort(vec.begin(),vec.end());
vec_sz mid = size/2;
return size % 2 == 0 ? (vec[mid] + vec[mid-1]) / 2 : vec[mid];
}
Student_info.cpp
#include "Student_info.h"
#include "grade.h"
#include <stdexcept>
/* #include <iostream> */ // Exercise 4-6: no longer required
using std::istream;
using std::vector;
using std::domain_error;
/* using std::cout; */ // Exercise 4-6: no longer required
// we are interested in sorting the Student_info object by the student's name
bool compare(const Student_info& x, const Student_info& y)
{
return x.name < y.name;
}
// Exercise 4-6: modified the following function
// now read student's name, and compute the overall_grade directly.
// Store only the student's name and final_grade to the Student_info object
// we use local variable to handle the rest
istream& read(istream& is, Student_info& s)
{
double midterm;
double final;
vector<double> homework;
is >> s.name >> midterm >> final;
// read and store all the student's homework scores (to the temporary vector<double> container)
read_hw(is, homework);
// compute the student's overall score, and store to the Student_info object
try
{
s.final_grade = grade(midterm, final, homework);
}
catch (domain_error e)
{
s.final_grade = -1; // indicating student has done no homework
}
return is;
}
// read homework grades from an input stream into a vector<double>
// (as defined in S4.1.3/57)
istream& read_hw(istream& in, vector<double>& hw)
{
if (in)
{
// get rid of previous contents
hw.clear();
// read homework grades
double x;
while (in >> x)
hw.push_back(x);
// clear the stream so that input will work for the next student
in.clear();
}
return in;
}
Header Files
grade.h
#ifndef GUARD_GRADE_H
#define GUARD_GRADE_H
//grade.h
#include <vector>
#include "Student_info.h"
double grade(double, double, double);
double grade(double, double, const std::vector<double>&);
// Exercise 4-6: the following function is no longer required.
/*
double grade(const Student_info&);
*/
#endif // GUARD_GRADE_H
#ifndef GUARD_MEDIAN_H
#define GUARD_MEDIAN_H
// median.h - final version
#include <vector>
double median(std::vector<double>);
#endif // GUARD_MEDIAN_H
Student_info.h
#ifndef GUARD_STUDENT_INFO_H
#define GUARD_STUDENT_INFO_H
// Student_info.h
#include <iostream>
#include <string>
#include <vector>
struct Student_info
{
std::string name;
// Exercise 4-6: no longer need to the followings in the Student_info object
/*
double midterm, final;
std::vector<double> homework;
*/
// Exercise 4-6: store only final_grade
double final_grade;
};
bool compare(const Student_info&, const Student_info&);
std::istream& read(std::istream&, Student_info&);
std::istream& read_hw(std::istream&, std::vector<double>&);
#endif // GUARD_STUDENT_INFO_H
Test Program
I will now run some tests using both the original and the revised programs. If the revised program report the same figures as the original program, we should be fairly confident that our revised program is (more or less) correct.
- Test 1 – submit all required inputs. i.e. Student’s name, mid-term score, final-term score, and homework scores.
- Test 2 – same as Test 1 except this time, we ommit the homework scores.
Test 1 Result
Original Program (Solution to Exercise 4-0)
Johnny 10 20 30 40 50
Fred 20 30 40 50 60
Joe 30 40 50 60 70
^Z
^Z
Fred 36
Joe 46
Johnny 26
Revised Program (Solution to Exercise 4-6)
Johnny 10 20 30 40 50
Fred 20 30 40 50 60
Joe 30 40 50 60 70
^Z
^Z
Fred 36
Joe 46
Johnny 26
*****************************************************************
*** Note: a grade of -1 implies student has done no homework. ***
*****************************************************************
Both programs gave the same results – as expected.
Test 2 Result
Original Program (Solution to Exercise 4-0)
Johnny 10 20
Fred 20 30
Joe 30 40 50 60 70
^Z
^Z
Fred student has done no homework
Joe 46
Johnny student has done no homework
Revised Program (Solution to Exercise 4-6)
Johnny 10 20
Fred 20 30
Joe 30 40 50 60 70
^Z
^Z
Fred -1
Joe 46
Johnny -1
*****************************************************************
*** Note: a grade of -1 implies student has done no homework. ***
*****************************************************************
Both programs gave the same results – as expected.
Conclusion
We have rewritten the program (from Solution to Exercise 4-0) as required by the problem. The test results suggest the revised program is reasonably correct.
Reference
Koenig, Andrew & Moo, Barbara E., Accelerated C++, Addison-Wesley, 2000