Exercise 5-11
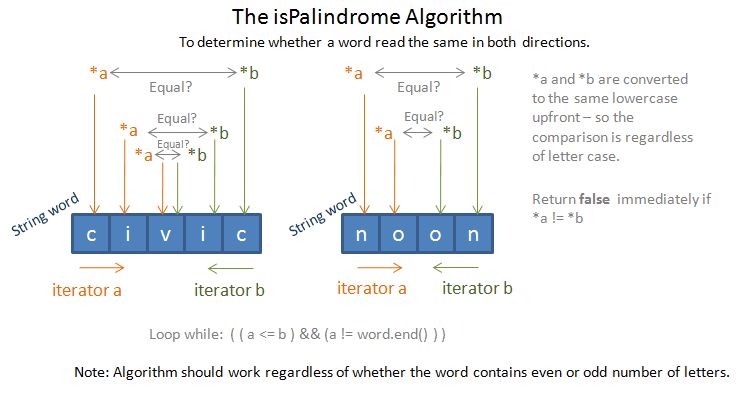
In text processing it is sometimes useful to know whether a word has any ascenders or descenders. Ascenders are the parts of lowercase letters that extend above the textline; in the English alphabet, the letters, b, d, f, h, k, l, and t have ascenders. Similarly, the descenders are the parts of lowercase letters that descend below the line; In English, the letters g, j, p, q, and y have descenders. Write a program to determine whether a word has any ascenders or descenders. Extend that program to find the longest word in the dictionary that has neither ascenders nor descenders.
Solution
This exercise is somewhat similar to the one we have just completed (Solution to Exercise 5-10), in which the user provides a list of words and the program filter and display the words that satisfy certain conditions.
Solution Strategy
Here is our Solution Strategy:
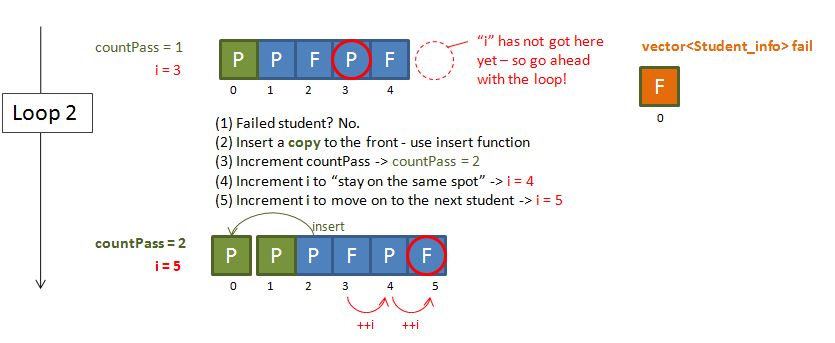
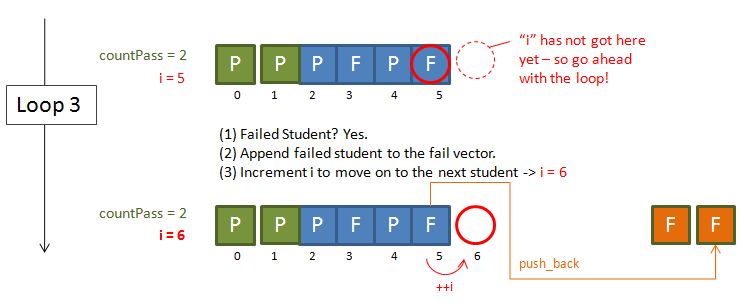
- Have a (bool type) function hasAscender to determine whether a given (string) word contains any ascenders (i.e. the letters b, d, f, h, k, l).
- Have a (bool type) function hasDescender to determine whether a given (string) word contains any Descenders (i.e. the letters g, j, p, q, and y).
- Use the usual while / cin / push_back method to read in a set of words.
- If the word contains any ascenders or descenders, append that word to a vector<string> container called interestingWords. Otherwise, append to another vector<string> container called boringWords.
- Have a function findLongest that is able to scan through a vector<string> container and return the longest (string) word.
- Print the vector<string> containers interestingWords and boringWords – in response to the challenge: Write a program to determine whether a word has any ascenders or descenders.
- Print the longest (string) word of the vector<string> container boringWords – in response to the challenge: Extend that program to find the longest word in the dictionary that has neither ascenders nor descenders.
A Side Note
The writing of the functions hasAscender and hasDescender will involve iterating through the letters within the given word, using multiple “hard-coded” if-conditions to determine whether the words container any ascenders / descenders. I do this because I wish to only use the techniques that have learnt so far. In this particular turns out to be okay as there is only a small handful of conditions need to be written. If we are faced with lots more conditions however, the if-condition techniques might not be as efficient (or the code might get too long).
A disclosure I would therefore like to make here is that in Chapter 6 (next chapter), the author would introduce a more compact method to deal with this type of scenario – using the standard library’s find function. Like the previous exercise, it looks like the author is trying to build up some grounds here before introducing us with the more compact methods.
The Project
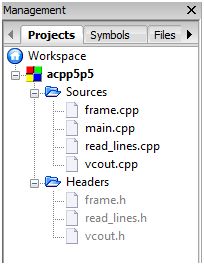
This section summarise all the C++ source and header files that I use to accomplish this challenge.
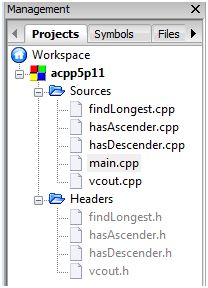
Source File List
Header File List
Source Files
main.cpp
#include <iostream> // cin, cout, endl
#include <string> // string
#include <vector> // vector
#include "hasAscender.h" // hasAscender
#include "hasDescender.h" // hasDescender
#include "findLongest.h" // findLongest
#include "vcout.h" // vcout
using std::cin;
using std::cout;
using std::endl;
using std::string;
using std::vector;
int main()
{
string word;
vector<string> interestingWords; // Words that contain either ascenders
// or descenders
vector<string> boringWords; // Words that contain neither ascenders
// nor descenders
// Populate vector
while (cin >> word) {
if (hasAscender(word) || hasDscender(word))
interestingWords.push_back(word);
else
boringWords.push_back(word);
}
// Print the interesting words
cout << "\nInteresting words (i.e. having ascenders or descenders):"
<< endl;
vcout(interestingWords);
// Print the boring words
cout << "\nBoring words (i.e. having neither ascenders nor descenders):"
<< endl;
vcout(boringWords);
// Print the longest boring word
cout << "\nThis is the longest boring word: " << findLongest(boringWords)
<< endl;
return 0;
}
findLongest.cpp
#include <string>
#include <vector>
using std::string;
using std::vector;
string findLongest(const vector<string>& words)
{
string longestWord;
for (vector<string>::const_iterator i = words.begin(); i != words.end(); ++i) {
if ( i->size() > longestWord.size() )
longestWord = *i;
}
return longestWord;
}
hasAscender.cpp
#include <string>
using std::string;
bool hasAscender(const string& s)
{
for (string::const_iterator i = s.begin(); i != s.end(); ++i) {
if (*i == 'b' || *i == 'd' || *i == 'f' || *i == 'h' || *i == 'k' ||
*i == 'l' )
return true;
}
return false;
}
hasDescender.cpp
#include <string>
using std::string;
bool hasDscender(const string& s)
{
for (string::const_iterator i = s.begin(); i != s.end(); ++i) {
if (*i == 'g' || *i == 'j' || *i == 'p' || *i == 'q' || *i == 'y')
return true;
}
return false;
}
vcout.cpp
#include <iostream>
#include <string> // string
#include <vector> // vector
using std::cout;
using std::endl;
using std::string;
using std::vector;
int vcout(const vector<string>& v)
{
for (vector<string>::const_iterator iter = v.begin();
iter != v.end(); ++iter)
{
cout << (*iter) << endl;
}
return 0;
}
Header Files
findLongest.h
#ifndef GUARD_FINDLONGEST_H #define GUARD_FINDLONGEST_H #include <string> #include <vector> std::string findLongest(const std::vector<std::string>&); #endif // GUARD_FINDLONGEST_H
hasAscender.h
#ifndef GUARD_HASASCENDER_H #define GUARD_HASASCENDER_H #include <string> bool hasAscender(const std::string&); #endif // GUARD_HASASCENDER_H
hasDescender.h
#ifndef GUARD_HASDESCENDER_H #define GUARD_HASDESCENDER_H #include <string> bool hasDscender(const std::string&); #endif // GUARD_HASDESCENDER_H
vcout.h
#ifndef GUARD_VCOUT_H #define GUARD_VCOUT_H #include <string> #include <vector> int vcout(const std::vector<std::string>&); #endif // GUARD_VCOUT_H
Test Program
I now run the program, and provide the list of words. As expected the program correctly identified the words containing (and not-containing) either ascenders or descenders. It also resolves the (first observed) longest word that has neither ascenders nor descenders.
the quick brown fox jumped over the fence eeeeeee aceimnorsvwxz nnnn i love c++ ^Z Interesting words (i.e. having ascenders or descenders): the quick brown fox jumped the fence love Boring words (i.e. having neither ascenders nor descenders): over eeeeeee aceimnorsvwxz nnnn i c++ This is the longest boring word: aceimnorsvwxz