Exercise 5-6
Rewrite the extract_fails function from S5.1.1/77 so that instead of erasing each failing student from the input vector students, it copies the records for the passing students to the beginning of students, and then uses the resize function to remove the extra elements from the end of students. How does the performance of this version compare with the one in S5.1.1/77?
Solution
The original (version 2) extract_fail function in the text book S5.1.1/77 looks like this – it uses the vector<XXX>::erase function.
{
Student_group fail;
Student_group::size_type i = 0;
// invariant: elements [0,i) of students represent passing grades
while (i != students.size())
{
if (fgrade(students[i]))
{
fail.push_back(students[i]);
students.erase(students.begin() + i);
}
else
++ i;
}
return fail;
}
Note that I have used the technique developed from my Solution to Exercise 5-4, in which all the vector<Student_info> are replaced by Student_group, using the C++ typedef. (Just trust me for now there is a typdef somewhere else that defines Student_group) I believe it makes sense to build on what we have learnt!
The newly “re-written” function will look like this it uses a combination of vector<XXX>::insert and vector<XXX>::resize functions.
Student_group extract_fails_v2_5p6(Student_group& students)
{
Student_group fail;
typedef Student_group::size_type VecSize;
VecSize countPass = 0;
// invariant: elements [0,i) of students represent passing grades
VecSize i = 0;
while (i != students.size())
{
if (fgrade(students[i]))
fail.push_back(students[i]);
else
{
students.insert(students.begin(), students[i++]);
++countPass;
}
++i;
}
students.resize(countPass);
return fail;
}
If after skimping through this new code and you fully understand the concepts / what’s going on, then congratulation you are done!
From a series of tests the new version happens to take 50% more time than the original version (when reaching around 10,000 lines of input) – performance results can be found at the bottom of the page under the Test Result section.
If you however would like to know more in details, such as how I derive this new code logic, then read on!
Code Logic – The insert/resize Method
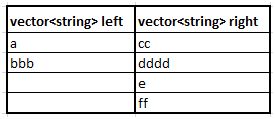
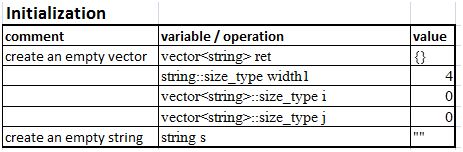
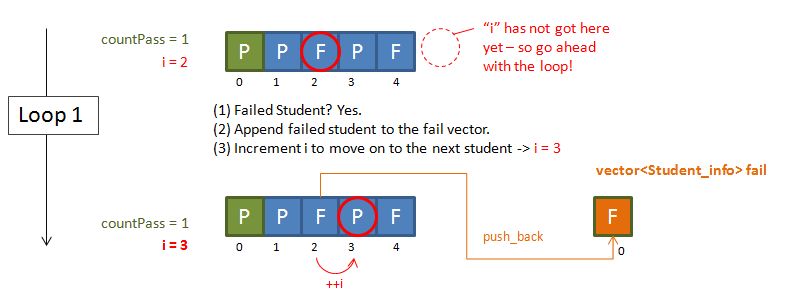
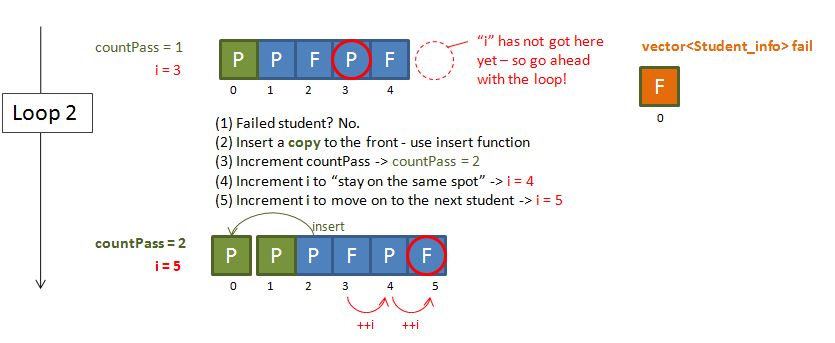
The way I derive the eventual code was simply doing some sketches on paper (In face this is how I usually solve problems – making sketches and pictures!). Below shows the diagrams that I drawn – essentially I started with a hypothetical example and just work my way through using logic. Some notes:
- The countPass is a counter to keep track of the number of passing students – this will be used later on to feed the vector<XXX>::resize function.
- The i, is just an incrementing variable (our good old friend), to facilitate a while loop.
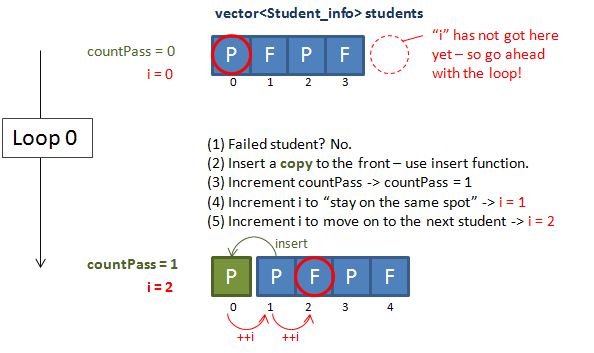
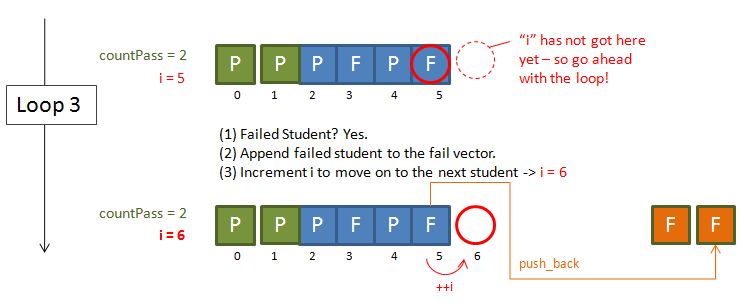
Have we reached the end of the vector? (yes)

Use the resize function to keep only the passing students in vector<Student_info> students.

And these are the final output!

An Important Learning – iterator
This exercise has exposed an interesting fact: iterator does NOT work when the underlying vector changes size! i.e. the following code will not work (even though it looks correct). One must use vector indexing instead! (I spent an hour debugging this – a hard lesson learnt!). Must be a feature of vector iterator vs vector index.
Student_group extract_fails_v2_5p6(Student_group& students)
{
Student_group fail;
Student_group::iterator i = students.begin();
Student_group::size_type countPass = 0;
// invariant: elements [0,i) of students represent passing grades
while (i != students.end())
{
if (fgrade(*i))
fail.push_back(*i);
else
{
students.insert(students.begin(), *i);
++countPass;
++i;
}
++i;
}
students.resize(countPass);
return fail;
}
The Project
Here are the complete set of header and source files that enable me to perform the test.
Source File List
Header File List
Source Files
main.cpp
#include <iostream>
#include <iomanip>
#include <ios>
#include <ctime>
#include "Student_info.h"
#include "Student_group.h" // switch between vector and list based Student_group here
#include "grade.h"
#include "extract_fails.h"
using std::cin;
using std::cout;
using std::endl;
using std::setprecision;
using std::streamsize;
int main()
{
Student_group students;
Student_info record;
// read and store all the student's data.
while (read(cin, record))
students.push_back(record);
// Extract the failed students and time-stamp it!
clock_t startTime = clock();
Student_group students_failed = extract_fails_v2(students);
/* Student_group students_failed = extract_fails_v2_5p6(students); */
clock_t endTime = clock();
clock_t clockTicksTaken = endTime - startTime;
double timeInSeconds = clockTicksTaken / (double) CLOCKS_PER_SEC;
streamsize prec = cout.precision();
cout << "Elapsed (in seconds): " << setprecision(30) << timeInSeconds
<< setprecision(prec) << endl;
// Uncomment the following block to display passing and failing students
/*
cout << endl;
// Report passing students
cout << "These students have passed." << endl;
for (Student_group::const_iterator iter = students.begin();
iter != students.end(); ++iter)
cout << iter->name << " (" << grade(*iter) << ")" << endl;
cout << endl;
// Report failing students
cout << "These students have failed." << endl;
for (Student_group::const_iterator iter = students_failed.begin();
iter != students_failed.end(); ++iter)
cout << iter->name << " (" << grade(*iter) << ")" << endl;
*/
return 0;
}
#include "Student_info.h"
#include "Student_group.h"
#include "grade.h"
// separate passing and failing student records
// derived from S5.1.1/77
Student_group extract_fails_v2(Student_group& students)
{
Student_group fail;
Student_group::size_type i = 0;
// invariant: elements [0,i) of students represent passing grades
while (i != students.size())
{
if (fgrade(students[i]))
{
fail.push_back(students[i]);
students.erase(students.begin() + i);
}
else
++ i;
}
return fail;
}
// Required by Exercise 5-6
Student_group extract_fails_v2_5p6(Student_group& students)
{
Student_group fail;
typedef Student_group::size_type VecSize;
VecSize countPass = 0;
// invariant: elements [0,i) of students represent passing grades
VecSize i = 0;
while (i != students.size())
{
if (fgrade(students[i]))
fail.push_back(students[i]);
else
{
students.insert(students.begin(), students[i++]);
++countPass;
}
++i;
}
students.resize(countPass);
return fail;
}
grade.cpp
#include <stdexcept>
#include <vector>
#include "grade.h"
#include "median.h"
#include "Student_info.h"
using std::domain_error;
using std::vector;
// definitions for the grade functions from S4.1/52, S4.1.2/54, S4.2.2/63
// compute a student's overall grade from midterm and final exam
// grades and homework grade (S4.1/52)
double grade(double midterm, double final, double homework)
{
return 0.2 * midterm + 0.4 * final + 0.4 * homework;
}
// compute a student's overall grade from midterm and final exam grades
// and vector of homework grades.
// this function does not copy its argument, because median (function) does it for us.
// (S4.1.2/54)
double grade(double midterm, double final, const vector<double>& hw)
{
if (hw.size() == 0)
throw domain_error("student has done no homework");
return grade(midterm, final, median(hw));
}
// this function computes the final grade for a Student_info object
// (S4.2.2/63)
double grade(const Student_info& s)
{
return grade(s.midterm, s.final, s.homework);
}
// predicate to determine whether a student failed
// (S5.1/75)
bool fgrade(const Student_info& s)
{
return grade(s) < 60;
}
// source file for the median function
#include <algorithm>
#include <stdexcept>
#include <vector>
using std::domain_error;
using std::sort;
using std::vector;
// compute the median of a vector<double>
double median(vector<double> vec)
{
typedef vector<double>::size_type vec_sz;
vec_sz size = vec.size();
if (size == 0)
throw domain_error("median of an empty vector");
sort(vec.begin(),vec.end());
vec_sz mid = size/2;
return size % 2 == 0 ? (vec[mid] + vec[mid-1]) / 2 : vec[mid];
}
Student_info.cpp
#include "Student_info.h"
using std::istream;
using std::vector;
// we are interested in sorting the Student_info object by the student's name
bool compare(const Student_info& x, const Student_info& y)
{
return x.name < y.name;
}
// read student's name, midterm exam grade, final exam grade, and homework grades
// and store into the Student_info object
// (as defined in S4.2.2/62)
istream& read(istream& is, Student_info& s)
{
// read and store the student's name and midterm and final exam grades
is >> s.name >> s.midterm >> s.final;
// read and store all the student's homework grades
read_hw(is, s.homework);
return is;
}
// read homework grades from an input stream into a vector<double>
// (as defined in S4.1.3/57)
istream& read_hw(istream& in, vector<double>& hw)
{
if (in)
{
// get rid of previous contents
hw.clear();
// read homework grades
double x;
while (in >> x)
hw.push_back(x);
// clear the stream so that input will work for the next student
in.clear();
}
return in;
}
Header Files
#ifndef GUARD_EXTRACT_FAILS_H
#define GUARD_EXTRACT_FAILS_H
// extract_fails.h
#include "Student_group.h"
Student_group extract_fails_v2(Student_group&);
Student_group extract_fails_v2_5p6(Student_group&);
#endif // GUARD_EXTRACT_FAILS_H
grade.h
#ifndef GUARD_GRADE_H
#define GUARD_GRADE_H
// grade.h
#include <vector>
#include "Student_info.h"
double grade(double, double, double);
double grade(double, double, const std::vector<double>&);
double grade(const Student_info&);
bool fgrade(const Student_info&);
#endif // GUARD_GRADE_H
#ifndef GUARD_MEDIAN_H
#define GUARD_MEDIAN_H
// median.h
#include <vector>
double median(std::vector<double>);
#endif // GUARD_MEDIAN_H
Student_group.h
#ifndef GUARD_STUDENT_GROUP_H
#define GUARD_STUDENT_GROUP_H
// Student_group.h
#include <list>
#include <vector>
#include "Student_info.h"
// ********************* AMEND THIS ***************************
// Solution to Exercise 5-4: Pick one of the followings
typedef std::vector<Student_info> Student_group;
//typedef std::list<Student_info> Student_group;
// ************************************************************
#endif // GUARD_STUDENT_GROUP_H
Student_info.h
#ifndef GUARD_STUDENT_INFO_H
#define GUARD_STUDENT_INFO_H
// Student_info.h
#include <iostream>
#include <string>
#include <vector>
struct Student_info
{
std::string name;
double midterm, final;
std::vector<double> homework;
};
bool compare(const Student_info&, const Student_info&);
std::istream& read(std::istream&, Student_info&);
std::istream& read_hw(std::istream&, std::vector<double>&);
#endif // GUARD_STUDENT_INFO_H
Test Program
Just simply amend the following line in the main() program accordingly for test purposes.
Student_group students_failed = extract_fails_v2(students);
/* Student_group students_failed = extract_fails_v2_5p6(students); */
Performance Comparison
I’ve run a few tests and recorded the job run time for the extract_fail step. from this it looks like the insert/resize method is actually slower than the erase method. But then, I guess it depends on the input file – i.e. depending on the ratio of passing students to failing students, the sequence of the passing and failing students, and potentially other factors.
|
v2 (erase) |
v2_5p6 (insert/resize) |
| 10 lines |
0.001 seconds |
0.000 seconds |
| 100 lines |
0.003 seconds |
0.004 seconds |
| 1,000 lines |
0.156 seconds |
0.212 seconds |
| 10,000 lines |
9.79 seconds |
16.6 seconds |
Reference
Koenig, Andrew & Moo, Barbara E., Accelerated C++, Addison-Wesley, 2000