Exercise 3-4
Write a program to report the length of the longest and shortest string in its input.
Solution
I notice that the solution to this problem will be somewhat similar to the Solution to Exercise 3-3 (identify number of distinct elements in a vector). Except this time we are determining the length of the longest and shortest (string) elements. I therefore expect the eventual program to be similar.
Strategy
- Ask user to provide the list of words so we can append the string elements to a vector, v.
- Compute the size of vector, N.
- If vector size is 0, output an error message (as we need at least 1 string). Exit program peacefully with return code 1.
- If vector size is 1, we compute the size of the string element v[0]. The length of the longest string, SL, will be the same as the length of the shortest string, SS.
- If vector size is 2 or above, we apply an algorithm to compute SL and SS (to be explained further below).
Algorithm
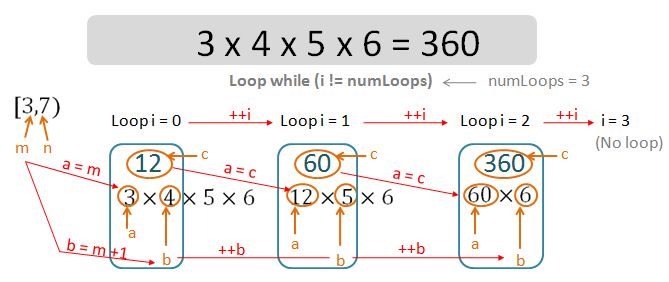
The algorithm (for the case of vector size of 2 or above) is described as followings:
- Notice that this time we do not need to sort the vector – the condition checks downstream will be sufficient to update SS and SL.
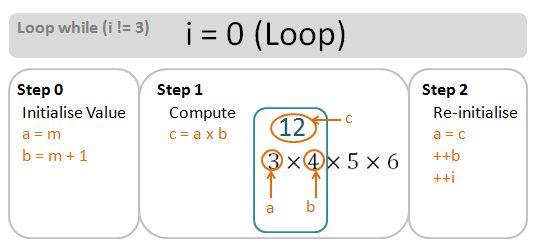
- We initialise SL and SS to the size of the first string element v[0]. SL and SS will be updated accordingly during the comparison step.
- We initialise the index B to 1. This will be used for comparing the length of the v[B] with respect to SS and SL.
- We perform N-1 number of comparisons between v[B] and the current SL and SS. (e.g. if there are 10 elements, we can only compare 9 sets of adjacent elements).
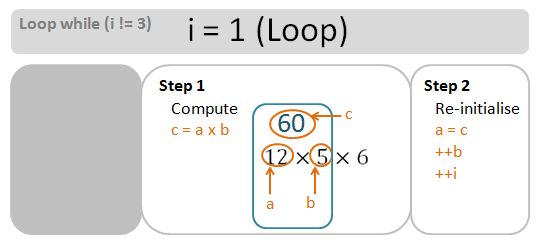
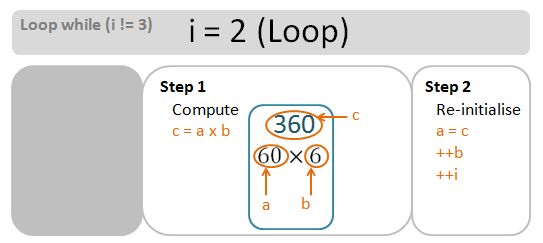
- During each comparison step, if v[B].size() is larger than SL, we re-assign SL to v[B].size().
- If v[B].size() is smaller than SS, we re-assign SS to v[B].size().
- (If the two element lengths are equal, we do nothing.)
- We then increment the indices B by 1 for the next comparisons.
- We display the final value of SS and SL – these are the lengths of the shortest and longest strings elements within the vector v.
The Program
Putting this all together, we have our full program.
#include <iostream>
#include <string>
#include <vector>
using std::cin; // <iostream>
using std::cout; // <iostream>
using std::endl; // <iostream>
using std::string; // <string>
using std::vector; // <string>
int main()
{
// display header message
cout << "***************************************************************\n"
"*** This program reports the longest and shortest strings ***\n"
"***************************************************************\n";
cout << endl;
// ask for a list of numbers and store the list as a vector
cout << "Enter a list of words one by one: ";
vector<string> v;
string x;
while (cin >> x)
v.push_back(x); // append new input to the vector
cout << endl;
// define and compute core vector variables
typedef vector<string>::size_type vecSize; // define a type for vector size related variables
vecSize N = v.size(); // number of elements in the vector
vecSize numLoops = N - 1; // number of (comparison) operators required
typedef string::size_type strSize; // define a type for string size related variables
strSize SL; // the length of the longest word
strSize SS; // the length of the shortest word
// Check vector size, action accordingly
if (N ==0 )
{
cout << "You need to enter at least 1 word! " << endl;
return 1;
}
else if (N ==1 )
{
SL = v[0].size();
cout << "Only 1 string supplied. The length of string = " << SL << endl;
return 0;
}
else
{
// display some results to console window
cout << "Vector size (number of words entered): " << N << endl;
cout << endl;
// declare new variables
vecSize A = 0; // vector index
vecSize B = 1; // vector index
SS = v[0].size(); // the length of the shortest word
SL = v[0].size(); // the length of the longest word
// Loop through the vector, compute ND, and compute SS and SL
for (vecSize i = 0; i != numLoops; ++i)
{
if (v[B].size() > SL)
{
SL = v[B].size();
}
if (v[B].size() < SS)
{
SS = v[B].size();
}
++B;
}
// Display final results
cout << endl;
cout << "Length of shortest word: " << SS << endl;
cout << "Length of longest word: " << SL << endl;
}
return 0;
}
Result
Below shows the results of the 3 sets of test:
- N = 0
- N=1
- N>=2
The results appear to agree well with the algorithm used.
N = 0
*************************************************************** *** This program reports the longest and shortest strings *** *************************************************************** Enter a list of words one by one: ^Z You need to enter at least 1 word! Process returned 1 (0x1) execution time : 3.156 s
N = 1
*************************************************************** *** This program reports the longest and shortest strings *** *************************************************************** Enter a list of words one by one: a23456789 ^Z Only 1 string supplied. The length of string = 9
N >= 2
*************************************************************** *** This program reports the longest and shortest strings *** *************************************************************** Enter a list of words one by one: a23456789 a23456 a2345b a234 a234567890 ^Z Vector size (number of words entered): 5 Length of shortest word: 4 Length of longest word: 10