Exercise 6-6
Note that the function from the previous exercise and the function from S6.2.2/113 and 6.2.3/115 do the same task. Merge these three analysis functions into a single function.
Some Background
This is regarding the “Compare Grading Scheme” sample codes as presented in chapter 6 of the book. The original codes may be found at Solution to Exercise 6-0 (Part 5 / 7).
One disclosure: though I eventually managed to complete this exercise and adjust all the codes, following a combination of trial-and-error (and a bit of Google-ing!), I have found it not an easy task to explain the solution to this entire problem – in some way I do find the idea of parsing a function as an argument to another function pretty abstract (and I believe things will only get better only after I have completed more C++ exercises and read on more.). For now, I shall do my best to explain my solution based on my understanding, which I hope will make sense! Please do forgive me if you ended up finding the following quite difficult to follow. I do wish I know a more systematic and simplified way to explain this solution! If you are not put off by this, read on!
Some Observations
OK. If you have also had a go running through the entirety of the “Compare Grading Scheme” project, you would likely have noticed that we have 3 very similar functions:
- average_analysis
- median_analysis
- optimistic_median_analysis
I shall recall these 3 functions below – note that they are pretty much identical, apart from the 4th argument of the transform function which corresponds to the associating grading scheme, respectively:
- average_grade
- grade_aux
- optimistic_median
average_analysis:
double average_analysis(const vector<Student_info>& students)
{
vector<double> grades;
transform(students.begin(), students.end(),
back_inserter(grades), average_grade);
return median(grades);
}
median_analysis:
double median_analysis(const vector<Student_info>& students)
{
vector<double> grades;
transform(students.begin(), students.end(), back_inserter(grades), grade_aux);
return median(grades);
}
optimistic_median_analysis:
double optimistic_median_analysis(const vector<Student_info>& students)
{
vector<double> grades;
transform(students.begin(), students.end(),
back_inserter(grades), optimistic_median);
return median(grades);
}
Opportunity to merge these 3 functions into one? Oh yes definitely!
Merging the three Analysis Functions into one
We note that the 3 functions are pretty much identical, apart from the 4th argument called by the transform function which corresponds to the associating grading scheme.
To merge the three functions into one, simply follow this strategy:
- Make a copy of one of the analysis function (say, the median_analysis function) and use it as our new baseline for building up the new “merged” function. Rename the function to something that sounds more generic. Let’s rename it to doAnalysis.
- Within the now doAnalysis function, rename that 4th argument called by the transform function with a more generic name. Let’s rename it to useGradeScheme. i.e. we use this as an “adaptor” for the 3 grading schemes (average_grade, grade_aux, and optimistic_median).
- Add a second parameter useGradeScheme to the doAnalysis function so we can parse the grade scheme into the doAnalysis implementation itself. We need to ensure this parameter takes the same form as grade_aux (which has the same form as average_grade, which also has the same form as optimistic_median). i.e. they all take this form: double XXXX(const Student_info&). To make things consistent, this new second parameter must also be of the same form. i.e. the second parameter shall be written as double useGradeScheme(const Student_info&).
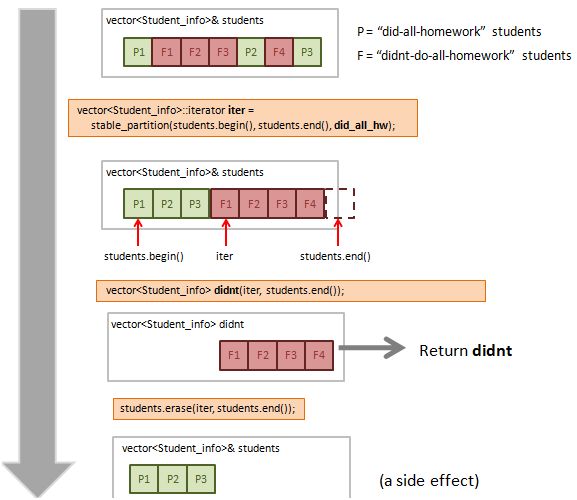
I summarise this strategy into a picture (which I hope will make it easier to understand).

Once we have completed the change, the new “merged” doAnalysis function shall look like this.
double doAnalysis(const vector<Student_info>& students,
double useGradeScheme(const Student_info&))
{
vector<double> grades;
transform(students.begin(), students.end(),
back_inserter(grades), useGradeScheme);
return median(grades);
}
Update the functions that are still calling the legacy analysis functions
Now that we have merged the 3 analysis functions into 1 new “merged” functions, we need to ensure all the whatever implementations that are still calling these 3 analysis functions (average_analysis, median_analysis, and optimistic_median_analysis) are also adjusted to use the new “merged” function. Otherwise those implementations would bump into errors as the 3 legacy analysis functions no longer exist! Our next task is therefore to identify the impacted implementations and make changes accordingly.
Fortunately, there is only one implementation impacted – the main function. The main function contains the following 3 lines, which still calls the legacy analysis functions (average_analysis, median_analysis, and optimistic_median_analysis) – as an argument to the function write_analysis.
write_analysis(cout, "median", median_analysis, did, didnt);
write_analysis(cout, "average", average_analysis, did, didnt);
write_analysis(cout, "median of homework turned in",
optimistic_median_analysis, did, didnt);
Because these analysis functions are used as an argument (which in this case, the 3rd argument) to another function, we must pay attention to that “another function” – write_analysis as we will likely need to adjust that as well. So let’s take a look at the write_analysis function:
void write_analysis(ostream& out,
const string& name,
double analysis(const vector<Student_info>&),
const vector<Student_info>& did,
const vector<Student_info>& didnt)
{
out << name << ": median(did) = " << analysis(did) <<
": median(didnt) = " << analysis(didnt) << endl;
return;
}
We know that the 3rd parameter double analysis(const vector<Student_info>&) corresponds to the legacy analysis function. When, say, median_analysis (as an argument) is parsed into this implementation (via this 3rd parameter) all the downstream analysis(XXX) within this implementation essentially get resolved into median_analysis(XXX). (likewise for the other two analysis functions).
As we have already mentioned, the median_analysis function shall be replaced by the new “merged” function called doAnalysis, which take this new form:
double doAnalysis(const vector<Student_info>& students,
double useGradeScheme(const Student_info&))
We must therefore adjust the analysis(XXX) accordingly to doAnalysis(XXX, XXX). i.e. we can replace the following:
out << name << ": median(did) = " << analysis(did) <<
": median(didnt) = " << analysis(didnt) << endl;
… with …
out << name << ": median(did) = " << doAnalysis(did, useGradeScheme) <<
": median(didnt) = " << doAnalysis(didnt, useGradeScheme) << endl;
We can declare the doAnalysis by simply doing a #include of the corresponding file.
For the useGradeScheme part however, we must parse it via the parameter. One way to do this is to replace the double analysis(const vector<Student_info>&), which we no longer need, to double useGradeScheme(const Student_info&), which we now need. I summarise this via a diagram below:

i.e. the now revised write_analysis function will look like this:
#include "doAnalysis.h" // doAnalysis
void write_analysis(ostream& out,
const string& name,
double useGradeScheme(const Student_info&),
const vector<Student_info>& did,
const vector<Student_info>& didnt)
{
out << name << ": median(did) = " << doAnalysis(did, useGradeScheme) <<
": median(didnt) = " << doAnalysis(didnt, useGradeScheme) <<
endl;
return;
}
Now that we have updated the write_analysis function, the logical next step is to update whatever implementation that call this write_analysis function, and adjust accordingly.
Let’s go back to the main function and look at the 3 lines again:
write_analysis(cout, "median", median_analysis, did, didnt);
write_analysis(cout, "average", average_analysis, did, didnt);
write_analysis(cout, "median of homework turned in",
optimistic_median_analysis, did, didnt);
We know from our new write_analysis function above, that the 3rd parameter is of the form double useGradeScheme(const Student_info&). It is therefore logical to parse an argumenet that satisfy this form. And we know that the useGradeScheme correspond to: average_grade, grade_aux, and optimistic_median. So, let’s do the replacement accordingly – I summarise this via a diagram.

The revised 3 lines in the main function will now look like this:
write_analysis(cout, "median", grade_aux, did, didnt);
write_analysis(cout, "average", average_grade, did, didnt);
write_analysis(cout, "median of homework turned in",
optimistic_median, did, didnt);
That’s pretty much all the changes required to solve this problem! (As I mentioned at the top of the post, I do find explaining the solution to this exercise not an easy task – if you still do not understand, I would recommend you to try compiling the files in the Project section below, run the program, test it out, confirm that it works, and try to understand how and why it has worked.
To see the complete project / source files, read on and try out!
The Project
To wrap things up, as usual, I shall publish my entire project here, including the source files and header files.
Source File List
Header File List
Source Files
main.cpp
#include <iostream> // cin, cout, endl
#include <vector> // vector
#include "Student_info.h" // Student_info
#include "did_all_hw.h" // did_all_hw
#include "write_analysis.h" // write_analysis
#include "grade_aux.h" // grade_aux
#include "average_grade.h" // average_grade
#include "optimistic_median.h" // optimistic_median
using std::cin;
using std::cout;
using std::endl;
using std::vector;
// Compare the Grading Scheme
// (S6.2.3/114)
int main()
{
// students who did and didn't do all their homework
vector<Student_info> did, didnt;
// read the student records and partition them
Student_info student;
while (read(cin, student)) {
if (did_all_hw(student))
did.push_back(student);
else
didnt.push_back(student);
}
// verify that the analyses will show us something
if (did.empty()) {
cout << "No student did all the homework!" << endl;
return 1;
}
if (didnt.empty()) {
cout << "No student did all the homework!" << endl;
return 1;
}
// do the analyses
write_analysis(cout, "median", grade_aux, did, didnt);
write_analysis(cout, "average", average_grade, did, didnt);
write_analysis(cout, "median of homework turned in",
optimistic_median, did, didnt);
return 0;
}
average.cpp
#include <vector> // vector
#include <numeric> // numeric
using std::vector;
using std::accumulate;
// Compute average of elements
// (S6.2.3/115)
double average(const vector<double>& v)
{
return accumulate(v.begin(), v.end(), 0.0) / v.size();
}
average_grade.cpp
#include "Student_info.h" // Student_info
#include "grade.h" // grade
#include "average.h" // average
// Compute the final grade using average of homework
// (S6.2.3/115)
double average_grade(const Student_info& s)
{
return grade(s.midterm, s.final, average(s.homework));
}
did_all_hw.cpp
#include <algorithm> // find
#include "Student_info.h" // Student_info
// Has the student done all the homework?
// (S6.2.1/110)
bool did_all_hw(const Student_info& s)
{
return ((find(s.homework.begin(), s.homework.end(), 0)) == s.homework.end());
}
doAnalysis.cpp
#include <vector> // vector
#include <algorithm> // transform
#include "Student_info.h" // Student_info
#include "median.h" // median
using std::vector;
using std::transform;
// Exercise 6-6: a consolidated auxiliary function
double doAnalysis(const vector<Student_info>& students,
double useGradeScheme(const Student_info&))
{
vector<double> grades;
transform(students.begin(), students.end(),
back_inserter(grades), useGradeScheme);
return median(grades);
}
grade.cpp
#include <stdexcept>
#include <vector>
#include "grade.h"
#include "median.h"
#include "Student_info.h"
using std::domain_error;
using std::vector;
// definitions for the grade functions from S4.1/52, S4.1.2/54, S4.2.2/63
// compute a student's overall grade from midterm and final exam
// grades and homework grade (S4.1/52)
double grade(double midterm, double final, double homework)
{
return 0.2 * midterm + 0.4 * final + 0.4 * homework;
}
// compute a student's overall grade from midterm and final exam grades
// and vector of homework grades.
// this function does not copy its argument, because median (function) does it for us.
// (S4.1.2/54)
double grade(double midterm, double final, const vector<double>& hw)
{
if (hw.size() == 0)
throw domain_error("student has done no homework");
return grade(midterm, final, median(hw));
}
// this function computes the final grade for a Student_info object
// (S4.2.2/63)
double grade(const Student_info& s)
{
return grade(s.midterm, s.final, s.homework);
}
grade_aux.cpp
#include "Student_info.h" // Student_info
#include "grade.h" // grade
#include <stdexcept> // domain_error
using std::domain_error;
// Auxiliary function to be parsed as argument to a function
// (S6.2.2/113)
double grade_aux(const Student_info& s)
{
try {
return grade(s);
} catch (domain_error) {
return grade(s.midterm, s.final, 0);
}
}
// source file for the median function
#include <algorithm>
#include <stdexcept>
#include <vector>
using std::domain_error;
using std::sort;
using std::vector;
// compute the median of a vector<double>
double median(vector<double> vec)
{
typedef vector<double>::size_type vec_sz;
vec_sz size = vec.size();
if (size == 0)
throw domain_error("median of an empty vector");
sort(vec.begin(),vec.end());
vec_sz mid = size/2;
return size % 2 == 0 ? (vec[mid] + vec[mid-1]) / 2 : vec[mid];
}
#include <vector> // vector
#include <algorithm> // remove_copy, back_inserter
#include "Student_info.h" // Student_info
#include "grade.h" // grade
#include "median.h" // median
using std::vector;
// median of the nonzero elements of s.homework, or 0 if no such elements exist
double optimistic_median(const Student_info& s)
{
vector<double> nonzero;
remove_copy(s.homework.begin(), s.homework.end(),
back_inserter(nonzero), 0);
if (nonzero.empty())
return grade(s.midterm, s.final, 0);
else
return grade(s.midterm, s.final, median(nonzero));
}
Student_info.cpp
#include "Student_info.h"
using std::istream;
using std::vector;
// we are interested in sorting the Student_info object by the student's name
bool compare(const Student_info& x, const Student_info& y)
{
return x.name < y.name;
}
// read student's name, midterm exam grade, final exam grade, and homework grades
// and store into the Student_info object
// (as defined in S4.2.2/62)
istream& read(istream& is, Student_info& s)
{
// read and store the student's name and midterm and final exam grades
is >> s.name >> s.midterm >> s.final;
// read and store all the student's homework grades
read_hw(is, s.homework);
return is;
}
// read homework grades from an input stream into a vector<double>
// (as defined in S4.1.3/57)
istream& read_hw(istream& in, vector<double>& hw)
{
if (in)
{
// get rid of previous contents
hw.clear();
// read homework grades
double x;
while (in >> x)
hw.push_back(x);
// clear the stream so that input will work for the next student
in.clear();
}
return in;
}
write_analysis.cpp
#include <iostream> // ostream, endl;
#include <vector> // vector
#include <string> // string
#include "Student_info.h" // Student_info
#include "doAnalysis.h" // doAnalysis
using std::ostream;
using std::endl;
using std::string;
using std::vector;
// Output result to compare the two groups of students who did and
// who didn't do all of their homework.
// (S6.2.3/113) | updated for Exercise 6-6
void write_analysis(ostream& out,
const string& name,
double useGradeScheme(const Student_info&),
const vector<Student_info>& did,
const vector<Student_info>& didnt)
{
out << name << ": median(did) = " << doAnalysis(did, useGradeScheme) <<
": median(didnt) = " << doAnalysis(didnt, useGradeScheme) <<
endl;
return;
}
Header Files
average.h
#ifndef GUARD_AVERAGE_H
#define GUARD_AVERAGE_H
// average.h
#include <vector>
double average(const std::vector<double>&);
#endif // GUARD_AVERAGE_H
average_grade.h
#ifndef GUARD_AVERAGE_GRADE_H
#define GUARD_AVERAGE_GRADE_H
// average_grade.h
#include "Student_info.h" // Student_info
double average_grade(const Student_info&);
#endif // GUARD_AVERAGE_GRADE_H
did_all_hw.h
#ifndef GUARD_DID_ALL_HW_H
#define GUARD_DID_ALL_HW_H
// did_all_hw.h
#include "Student_info.h" // Student_info
bool did_all_hw(const Student_info&);
#endif // GUARD_DID_ALL_HW_H
doAnalysis.h
#ifndef GUARD_DOANALYSIS_H
#define GUARD_DOANALYSIS_H
#include <vector>
#include "Student_info.h"
double doAnalysis(const std::vector<Student_info>&,
double useGradeScheme(const Student_info&));
#endif // GUARD_DOANALYSIS_H
grade.h
#ifndef GUARD_GRADE_H
#define GUARD_GRADE_H
// grade.h
#include <vector>
#include "Student_info.h"
double grade(double, double, double);
double grade(double, double, const std::vector<double>&);
double grade(const Student_info&);
#endif // GUARD_GRADE_H
grade_aux.h
#ifndef GUARD_GRADE_AUX_H
#define GUARD_GRADE_AUX_H
// grade_aux.h
#include "Student_info.h" // Student_info
double grade_aux(const Student_info&);
#endif // GUARD_GRADE_AUX_H
#ifndef GUARD_MEDIAN_H
#define GUARD_MEDIAN_H
// median.h
#include <vector>
double median(std::vector<double>);
#endif // GUARD_MEDIAN_H
#ifndef GUARD_OPTIMISTIC_MEDIAN_H
#define GUARD_OPTIMISTIC_MEDIAN_H
// optimistic_median.h
#include "Student_info.h" // Student_info
double optimistic_median(const Student_info&);
#endif // GUARD_OPTIMISTIC_MEDIAN_H
Student_info.h
#ifndef GUARD_STUDENT_INFO_H
#define GUARD_STUDENT_INFO_H
// Student_info.h
#include <iostream>
#include <string>
#include <vector>
struct Student_info
{
std::string name;
double midterm, final;
std::vector<double> homework;
};
bool compare(const Student_info&, const Student_info&);
std::istream& read(std::istream&, Student_info&);
std::istream& read_hw(std::istream&, std::vector<double>&);
#endif // GUARD_STUDENT_INFO_H
write_analysis.h
#ifndef GUARD_WRITE_ANALYSIS_H
#define GUARD_WRITE_ANALYSIS_H
// write_analysis.h
#include <iostream> // ostream;
#include <vector> // vector
#include <string> // string
#include "Student_info.h" // Student_info
void write_analysis(std::ostream&,
const std::string&,
double useGradeScheme(const Student_info&),
const std::vector<Student_info>&,
const std::vector<Student_info>&);
#endif // GUARD_WRITE_ANALYSIS_H
Test Program
I now submit the same input (as the test to the original program / Solution to Exercise 6-0 (Part 5 / 7)). The test shows that we get the same result, implying the code updates are not causing observable issues.
pete 100 100 100 100 100
jon 90 90 0 0 0
mary 50 50 50 50 50
anna 40 40 0 0 0
gary 80 80 0 80 0
bob 100 100 100 0 0
ken 20 88 99 44 66
jay 99 39 40 80 0
bill 20 88 0 39 0
^Z
^Z
median: median(did) = 65.6: median(didnt) = 49.7
average: median(did) = 67.0667: median(didnt) = 52.7
median of homework turned in: median(did) = 65.6: median(didnt) = 57.1
Reference
Koenig, Andrew & Moo, Barbara E., Accelerated C++, Addison-Wesley, 2000